























































Understanding the persistence layer
SAP HANA's persistence layer manages logging of all the transactions in order to provide standard backup and restore functions. Both the row stores and column stores interact with the persistence layer. It offers regular savepoints, and also logging of all database transaction since the last savepoint.
The persistence layer is responsible for the durability and atomicity of transactions. The persistence layer manages both data and log volumes on the disk, and also provides interfaces to read and write data that is leveraged by all the storage engines. This layer is built based on the persistency layer of MaxDB, SAP's traditional relational database. The persistency layer guarantees that the database is restored to the most recent committed state after a restart, and these transactions are either completely executed or completely rolled back. To accomplish this efficiently, it uses a blend of write-ahead logs, shadow paging, and savepoints.
To enable scalability in terms of data volumes and the number of application requests, the SAP HANA database supports scale-up and scale-out. Keeping data in the main memory brings up the question of what will happen in the case of a loss of power.
In database technology, atomicity, consistency, isolation, and durability (ACID) are a set of requirements that guarantees that the database transactions are processed reliably:
A transaction has to be atomic. This means the transaction should be either executed completely or fail completely. The database state should be unchanged, and the entire transaction has to fail if a part of it fails.
Consistency of a database must be unspoiled by the transactions that it performs.
Isolation ensures that all transactions are independent.
Durability means that there is no change in the state of a transaction, that is, a transaction will remain committed after it has been committed.
While the first three requirements are not affected by the in-memory database concepts, durability is the lone requirement that cannot be met by storing data in the main memory. The main memory is a volatile storage; its content will be cleared when power is switched off. To make data persistent, non-volatile storage (such as hard drives, SSD, or flash devices) have to be used.
Further reading
The storage used by a database to store data is divided into pages. When data changes occur due to transactions, the changed pages are marked and written to the non-volatile storage at regular intervals. In addition to this, all changes made by the transactions are captured by database log. All the committed transactions generate a log entry, and these are written to non-volatile storage. This confirms that all transactions are stored permanently. The following diagram illustrates this using the example of SAP HANA. All the changed pages are saved in the form of savepoints, which are asynchronously written to persistent storage at regular intervals (by default, every five minutes). The log is written synchronously, that is, transaction does not return before the corresponding log entry that has been written to the persistent storage.
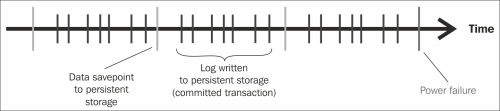
After a power failure, the database can be restarted like a disk-based database. Database pages from the savepoints are restored, and then the database logs are applied (rolled forward) to restore the changes that were not captured in the savepoints. This ensures that the database can be restored in the memory to exactly the same state as it was before the power failure.
The SAP in-memory database holds the bulk of its data in the memory for maximum performance. It still depends on persistent storage to provide a fallback in case of failure. The log captures all changes done by the database transactions (redo logs).
Data and undo log information (parts of data) are automatically saved to the disk at regular savepoints. The log is also saved to the disk continuously and synchronously after each commit of a database transaction (waiting for the end of a disk write operation).
The database can be restarted after a power failure, just like a disk-based database:
The system is normally restarted (lazy reloading of tables to keep the restart time short)
The system returns to its last consistent state (by replaying the redo log since the last savepoint)
For more information, refer to the following link:




