























































HTML and the DOM
When a browser loads an HTML page, it creates a tree that represents that page. This tree is based on the DOM specification. It uses tags to determine where each node starts and ends.
Consider the following piece of HTML code:
<html> <head> <title>Sample Page</title> </head> <body> <p>This is a paragraph.</p> <div> <p>This is a paragraph inside a div.</p> </div> <button>Click me!</button> </body> </html>
The browser will create the following hierarchy of nodes:
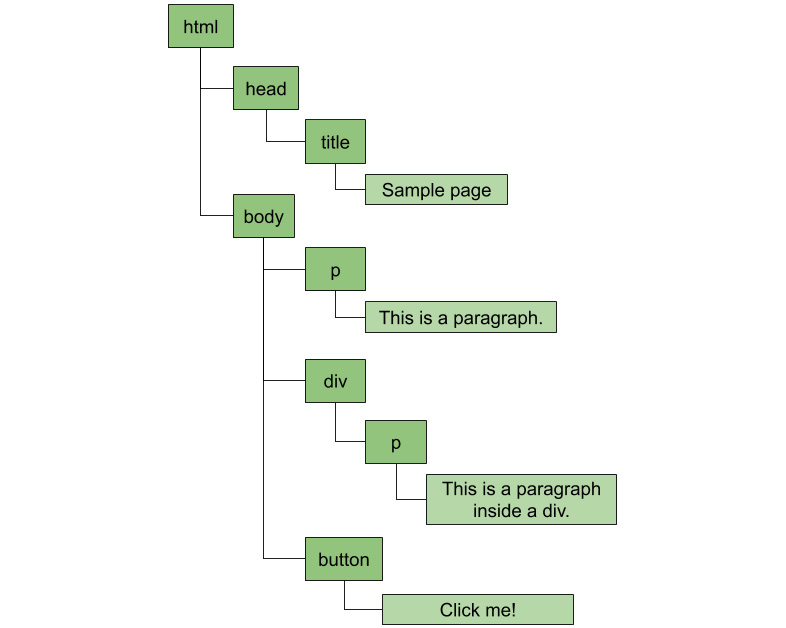
Figure 1.1: A paragraph node contains a text node
Everything becomes a node. Texts, elements, and comments, all the way up to the root of the tree. This tree is used to match...








