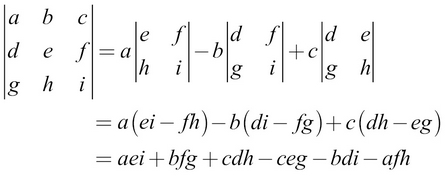Tensor/matrix operations
Transpose
Transpose is an important operation defined for matrices or tensors. For a matrix, the transpose is defined as follows:
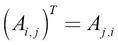
Here, AT denotes the transpose of A.
An example of the transpose operation can be illustrated as follows:
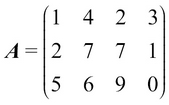
After the transpose operation:
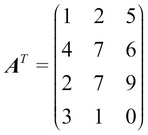
For a tensor, transpose can be seen as permuting the dimensions order. For example, let's define a tensor S, as shown here:
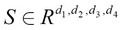
Now a transpose operation (out of many) can be defined as follows:
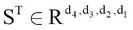
Multiplication
Matrix multiplication is another important operation that appears quite frequently in linear algebra.
Given the matrices 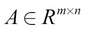 and
and 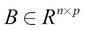 , the multiplication of A and B is defined as follows:
, the multiplication of A and B is defined as follows:
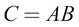
Here, 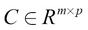 .
.
Consider this example:
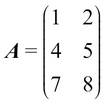
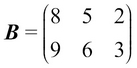
This gives
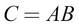
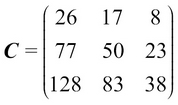
, and the value of C is as follows:
Element-wise multiplication
Element-wise matrix multiplication (or the Hadamard product) is computed for two matrices that have the same shape. Given the matrices 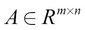 and
and 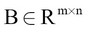 , the element-wise multiplication of A and B is defined as follows:
, the element-wise multiplication of A and B is defined as follows:
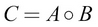
Here, 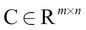
Consider this example:
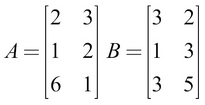
This gives 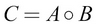 , and the value of C is as follows:
, and the value of C is as follows:
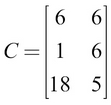
Inverse
The inverse of the matrix A is denoted by A -1, where it satisfies the following condition:
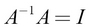
Inverse is very useful if we are trying to solve a system of linear equations. Consider this example:
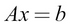
We can solve for x like this:
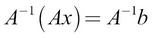
This can be written as, 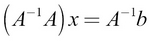 using the associative law (that is,
using the associative law (that is, 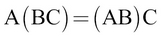 ).
).
Next, we will get 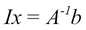 because
because 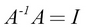 , where I is the identity matrix.
, where I is the identity matrix.
Lastly, 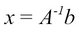 because
because 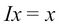 .
.
For example, polynomial regression, one of the regression techniques, uses a linear system of equations to solve the regression problem. Regression is similar to classification, but instead of outputting a class, regression models output a continuous value. Let's look at an example problem: given the number of bedrooms in a house, we'll calculate the real-estate value of the house. Formally, a polynomial regression problem can be written as follows:
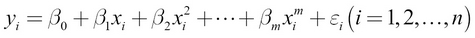
Here,
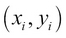
is the ith data input, where xi is the input, yi is the label, and 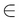 is noise in data. In our example, x is the number of bedrooms and y is the price of the house. This can be written as a system of linear equations as follows:
is noise in data. In our example, x is the number of bedrooms and y is the price of the house. This can be written as a system of linear equations as follows:

However, A-1 does not exist for all A. There are certain conditions that need to be satisfied in order for the inverse to exist for a matrix. For example, to define the inverse, A needs to be a square matrix (that is, 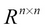 ). Even when the inverse exists, we cannot always find it in the closed form; sometimes it can only be approximated with finite-precision computers. If the inverse exists, there are several algorithms for finding it, which we will be discussing here.
). Even when the inverse exists, we cannot always find it in the closed form; sometimes it can only be approximated with finite-precision computers. If the inverse exists, there are several algorithms for finding it, which we will be discussing here.
Note
When it is said that A needs to be a square matrix for the inverse to exist, I refer to the standard inversion. There exists variants of inverse operation (for example, Moore-Penrose inverse, also known as pseudoinverse) that can perform matrix inversion on general
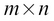
matrices.
Finding the matrix inverse – Singular Value Decomposition (SVD)
Let's now see how we can use SVD to find the inverse of a matrix A. SVD factorizes A into three different matrices, as shown here:
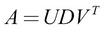
Here the columns of U are known as left singular vectors, columns of V are known as right singular vectors, and diagonal values of D (a diagonal matrix) are known as singular values. Left singular vectors are the eigenvectors of 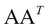 and the right singular vectors are the eigenvectors of
and the right singular vectors are the eigenvectors of 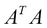 . Finally, the singular values are the square roots of the eigenvalues of
. Finally, the singular values are the square roots of the eigenvalues of 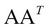 and
and 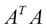 . Eigenvector
. Eigenvector 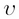 and its corresponding eigenvalue
and its corresponding eigenvalue 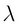 of the square matrix A satisfies the following condition:
of the square matrix A satisfies the following condition:
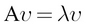
Then if the SVD exists, the inverse of A is given by this:
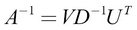
Since D is diagonal, D-1 is simply the element-wise reciprocal of the nonzero elements of D. SVD is an important matrix factorization technique that appears in many occasions in machine learning. For example, SVD is used for calculating Principal Component Analysis (PCA), which is a popular dimensionality reduction technique for data (a purpose similar to that of t-SNE that we saw in Chapter 4, Advanced Word2vec). Another, more NLP-oriented application of SVD is document ranking. That is, when you want to get the most relevant documents (and rank them by relevance to some term, for example, football), SVD can be used to achieve this.
Norms
Norm is used as a measure of the size of the matrix (that is, of the values in the matrix). The pth norm is calculated and denoted as shown here:
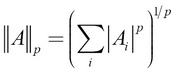
For example, the L2 norm would be this:
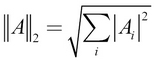
Determinant
The determinant of a square matrix, denoted by 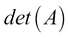 , is the product of all the eigenvalues of the matrix. Determinant is very useful in many ways. For example, A is invertible if and only if the determinant is nonzero. The following equation shows the calculations for the determinant of a
, is the product of all the eigenvalues of the matrix. Determinant is very useful in many ways. For example, A is invertible if and only if the determinant is nonzero. The following equation shows the calculations for the determinant of a 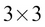 matrix:
matrix: