























































YARN in the real world – Computation beyond MapReduce
The previous discussions have been a little abstract, so in this section, we will explore a few existing YARN applications to see just how they use the framework and how they provide a breadth of processing capability. Of particular interest is how the YARN frameworks take very different approaches to resource management, I/O pipelining, and fault tolerance.
The problem with MapReduce
Until now, we have looked at MapReduce in terms of API. MapReduce in Hadoop is more than that; up until Hadoop 2, it was the default execution engine for a number of tools, among which were Hive and Pig, which we will discuss in more detail later in this book. We have seen how MapReduce applications are, in fact, chains of jobs. This very aspect is one the biggest pain points and constraining factors of the frameworks. MapReduce checkpoints data to HDFS for intra-process communication:
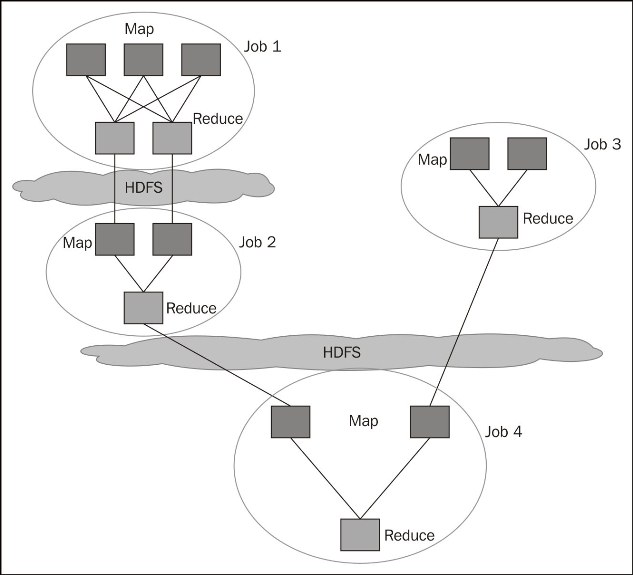
A chain of MapReduce jobs
At the end of each reduce phase, output is written...





