























































Loading JSON into Spark
Spark can also access JSON data for manipulation. Here we have an example that:
- Loads a JSON file into a Spark data frame
- Examines the contents of the data frame and displays the apparent schema
- Like the other preceding data frames, moves the data frame into the context for direct access by the Spark session
- Shows an example of accessing the data frame in the Spark context
The listing is as follows:
Our standard includes for Spark:
from pyspark import SparkContextfrom pyspark.sql import SparkSession sc = SparkContext.getOrCreate()spark = SparkSession(sc)
Read in the JSON and display what we found:
#using some data from file from https://gist.github.com/marktyers/678711152b8dd33f6346df = spark.read.json("people.json")df.show()
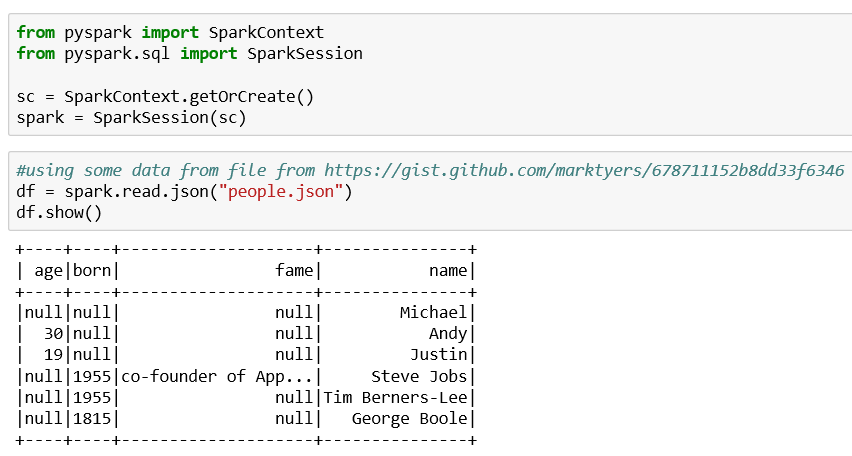
I had a difficult time getting a standard JSON to load into Spark. Spark appears to expect one record of data per list of the JSON file versus most JSON I have seen pretty much formats the record layouts with indentation and the like.
Note
Notice the use...













