There are various technologies that can be used for developing a website. The content presented to end users using web browsers can also exist in various other formats and patterns.
As discussed earlier, dynamic generation or manipulation of the contents of web page are also possible. Page content can also include static content rendered with HTML and associated technologies, or presented and created on the fly. Content can also be retrieved using third-party sources and presented to end users.
Web browsers are used for client-server based GUI interaction exploring web content. The browser address bar is supplied with the web address or URL, and the requested URL is communicated to the server (host) and response is received, that is, loaded by the browser. This obtained response or page source can be further explored, and the desired content can be searched in raw format.
Users are free to choose their web browser. We will be using Google Chrome for most of the book, installed on the Windows operating system (OS).
The HTML source for pages will be frequently opened and investigated for required content and resources during scraping process. Right click the web page. A menu will then appear where you can find the View page source option. Alternatively, press Ctrl + U.
Let's look at an example of web scraping by following these steps:
- Go to https://www.google.com on in your chosen browser
- Enter Web Scraping in the search box
- Press Enter or click the Google search button on the page
- You should see something similar to the following screenshot:

Search results for web scraping from Google
Google has provided us with the search information we have asked for. This information is displayed in paragraphs and numerous links are also presented. The information displayed is interactive, colorful, and presented in maintained structure with the search contents adopted in the layout.
This is the frontend content we are viewing. This content is provided to us dynamically based on our interaction with Google. Let's now view the raw content that has been provided to us.
- Right-click the web page. A menu will then appear where you can find the View page source option. Alternatively, press Ctrl + U. Here, a new tab will be opened with the HTML source of the page. Check for view-source at the start of the URL in the browser:

HTML page source: search results for web scraping from Google
We are now accessing the HTML source of the page displayed in the previous screenshot. HTML tags and JavaScript codes can be easily seen, but are not presented in the proper format. These are the core contents that the browser has rendered to us.
Search for some text, displayed on the normal page view, in the page source. Identify how and where the text, links, and images are found in the page source. You will be able to find the text in the page source within HTML tags (but not always, as we shall see!)
Web development can be done using various technologies and tools, as we discussed in the previous sections. Web page content displayed by browsers might not always be available inside HTML tags when its source is explored. Content can also exist inside scripts or even on third-party links. This is what makes web scraping often challenging, and thus demands the latest tools and technologies that exist for web development.
Let's explore another case, with the browsing procedure that we applied in the Case 1 section:
- Search for Top Hotels in USA for 2018 on Google and choose any hotel name you like.
- Search for the hotel name in Google directly (or you can ignore the preceding step). For example, try The Peninsula Chicago.
- Google will load the searched hotel's details' along with a map and booking and reviews sections. The result of this will be similar to the following screenshot:

Google search result for The Peninsula Chicago
- On the left-hand side, you can find the link for Google reviews. After clicking the link, a new page will pop up, as seen in the following screenshot:

Google reviews page from the search page
- Right-click on the pop-up review page and select View page source, or press Ctrl + U for the page source.
Try to find the reviews and response texts by users from the page source.
Developer tools (or DevTools) are found embedded within most browsers on the market today. Developers and end users alike can identify and locate resources and search for web content that is used during client-server communication, or while engaged in an HTTP request and response.
DevTools allow a user to examine, create, edit, and debug HTML, CSS, and JavaScript. They also allow us to handle performance problems. They facilitate the extraction of data that is dynamically or securely presented by the browser.
DevTools will be used for most data extraction cases, and for cases similar to Case 2 from the page source section previously mentioned. For more information on developer tools, please explore these links:
In Google Chrome, we can load DevTools by following any of these instructions:
- Simply press Ctrl + Shift + I
- Another option is to right-click on the page and press the Inspect option
- Alternatively, if accessing Developer tools through the Chrome menu, click More tools | Developer tools:

Loading the Chrome DevTools for a reviews page
The preceding screenshot displays the Developer Tools panels: Elements, Console, Network, Sources, and so on. In our case, let's look for some text from the review page. Following these steps will allow us to find it:
- Open the Network panel inside Developer Tools.
- Select the XHR filter option. (Multiple resources such as HTML files, images, and JSON data will be found listed under the Name panel.)
- We need to traverse through the resources under the Name pane looking for the chosen text fragment we seek. (The Response tab displays the content of chosen resources.)
- A resource beginning with reviewDialog? is found, containing the searched-for text.
The steps outlined here for searching review text form one of the most commonly used techniques for locating exact content. These steps are followed normally when the content is obtained dynamically and is not found inside the page source.
There are various panels in Developer tools that are related to specific functions provided to web resources or for analysis, including Sources, Memory, Performance, and Networks. We will be exploring a few panels found in Chrome DevTools, as follows:
The specific names of panels found in browser-based DevTools might not be the same across all browsers.
- Elements: Displays the HTML content of the page viewed. This is used for viewing and editing the DOM and CSS, and also for finding CSS selectors and XPath.
HTML elements displayed or located from the Elements panel may not be available in the page source.
- Console: Used to run and interact with JavaScript code, and view log messages:
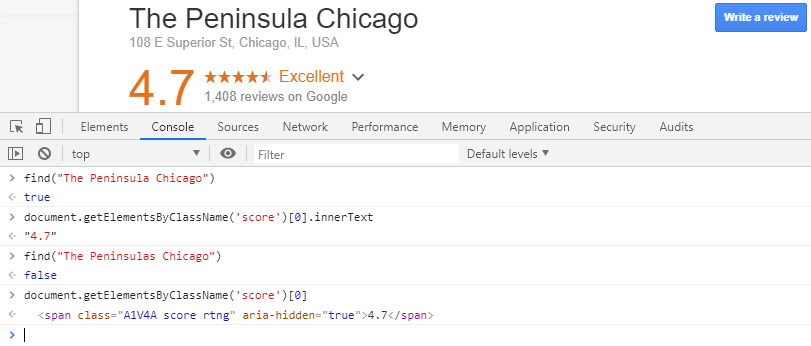
The Console panel inside Chrome DevTools
- Sources: Used to navigate pages, view available scripts and documents sources. Script-based tools are available for tasks such as script execution (that is, resuming, pausing), stepping over function calls, activating and deactivating breakpoints, and also handling the exceptions such as pausing exceptions, if encountered:
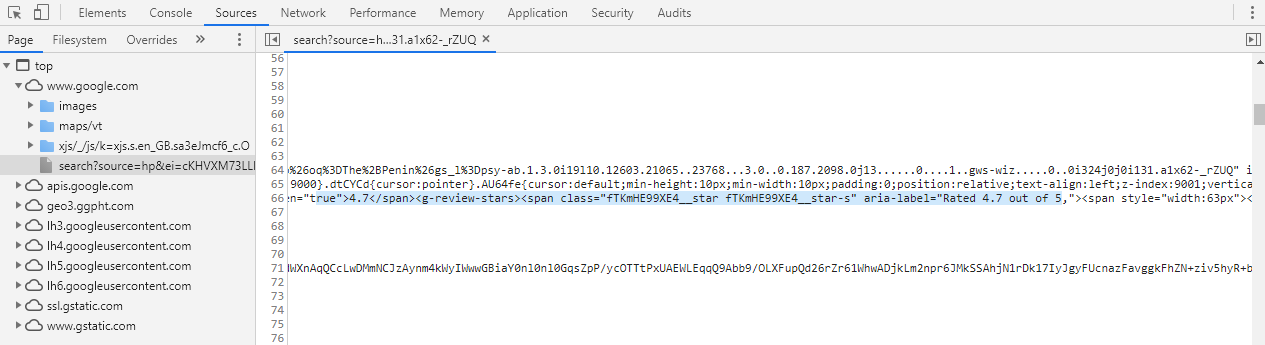
The Sources panel from Chrome DevTools
- Network: Provides us with HTTP request and response-related resources, and shows the network resources used while loading a page. Resources found inside Network feature options such as recording data to network logs, capturing screenshots, filtering web resources (JavaScript, images, documents, and CSS), searching web resources, and grouping web resources, and can be used for debugging tasks too:

The Chrome DevTools Network panel
Requests can also be filtered by type:
- All: Lists all requests related to the network, including document requests, image requests, and font and CSS requests. Resources are placed in order of loading.
- XHR: Lists XmlHttpRequest objects load AJAX content on the fly
- JS: Lists requested scripts files
- CSS: Lists requested style files
- Img: Lists requested image files
- Doc: Lists requested HTML or web documents
- Other: Any unlisted type of request related resources
For filter options listed previously, there are tabs (Headers, Preview, Response, Timing, Cookies) for selected resources in the Name panel:
- Headers: Loads HTTP header data for a particular request. Information revealed includes request URLs, request methods, status codes, request headers, query string parameters, and POST parameters.
- Preview: Loads a formatted preview of the response.
- Response: Loads the response to a particular request.
- Timing: To view time breakdown information.
- Cookies: Loads cookie information for the resources selected in the Name panel.
From the scraping point of view, the DevTools Network panel is useful for finding and analyzing web resources. This information can be useful for retrieving data and choosing methods to process these resources.
There are various elements provided on the Network panel which are explained below:
- Performance: The Screenshots page and Memory timeline can be recorded. The visual information obtained is used to optimize website speed, improving load times and analyzing runtime performance. In earlier Chrome versions, information provided by the Performance panel used to exist inside a panel named Timeline:

The Performance panel in Chrome DevTools
- Memory: This panel was also known as panel profiles in earlier Chrome versions. Information obtained from this panel is used to fix memory problems and track down memory leaks. The Performance and Memory panels are also used by developers to analyze overall website performance.
- Application: The end user can inspect and manage storage for all loaded resources, including cookies, sessions, application cache, images, and databases.
After exploring the HTML page source and DevTools, we now have a general idea of where data can be explored or searched for. Overall, scraping involves extracting data from web pages, and we need to identify or locate the resource carrying the data we want to extract. Before proceeding with data exploration and content identification, it will be beneficial to plan and identify page's URLs or links that contain data.
Users can pick any URL for scraping purposes. Page links or URLs that point to a single page might also contain pagination links or links that redirect the user to other resources. Content distributed across multiple pages needs to be crawled individually by identifying the page URL. There exist sitemaps and robots.txt files, made available by websites, that contain links and directives for crawling-related activities.
A sitemap.xml file is an XML file that holds the information related to page URLs. Maintaining a sitemap is an easy way to inform search engines about the URLs the website contains. Search-engine-based scripts crawl the links in sitemaps and use the links found for indexing and various purposes such as search engine optimization (SEO).
URLs found inside a sitemap generally exist with additional information such as created date, modified date, new URL, removed URL, and many more. These are normally found wrapped in XML tags. In this case, we have <sitemap> with <loc>, as shown in the following screenshot:
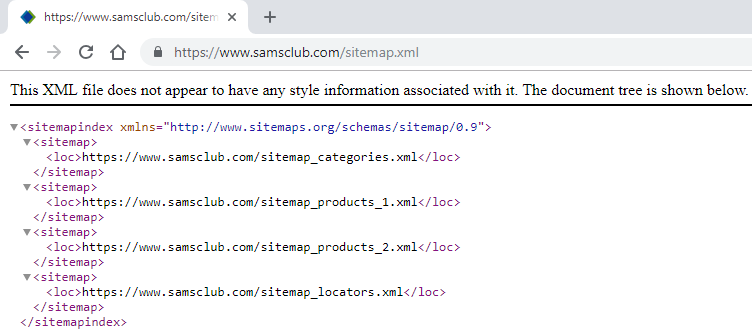
Sitemap content from https://www.samsclub.com/
Sitemaps are accessed by adding sitemap.xml to the URL, for example, https://www.samsclub.com/sitemap.xml.
There's no obligation for sitemap.xml to exist for all websites. Sitemaps might carry individual URLs for pages, products, categories, and inner sitemap files that can be processed easily for scraping purposes, instead of exploring web pages for links and collecting all of them from each website, one by one.
robots.txt, also known as the robots exclusion protocol, is a web-based standard used by websites to exchange information with automated scripts. In general, robots.txt carries instructions regarding URLs, pages, and directories on their site to web robots (also known as web wanderers, crawlers, or spiders) using directives such as Allow, Disallow, Sitemap, and Crawl-delay to direct their behavior:
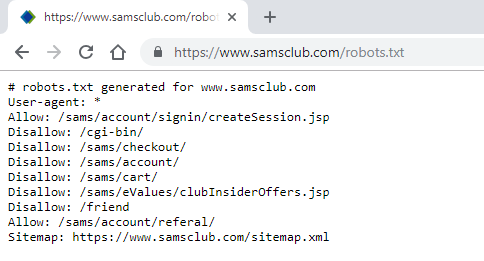
The robots.txt file from https://www.samsclub.com/
For any provided website addresses or URLs, the robots.txt file can be accessed by adding robots.txt to the URL, for example, https://www.samsclub.com/robots.txt or https://www.test-domainname.com/robots.txt.
As seen in the preceding screenshot (The robots.txt file from https://www.samsclub.com/), there are Allow, Disallow, and Sitemap directives listed inside https://www.samsclub.com/robots.txt:
- Allow permits web robots to access the link it carries
- Disallow conveys restriction of access to a given resource
- User-agent: * shows that the listed directives are to be followed by all agents
For access violation caused by web crawlers and spammers, the following steps can be taken by website admins:
- Enhance security mechanisms to restrict any unauthorized access to the website
- Impose a block on the traced IP address
- Take necessary legal action
Web crawlers should obey the directives mentioned in the file, but for normal data extraction purposes, there's no restriction imposed until and unless the crawling scripts hamper website traffic, or if they access personal data from the web. Again, it's not obligatory that a robots.txt file should be available on each website.



































































