























































Designing the high-level architecture
The high-level architecture of the system that we are planning to build contains two parts. The first part is the model, which we will build using the historical transaction data. Once this model has been created, we will use it in the second part with new data to determine whether a particular transaction falls in a cluster of suspicious transactions.
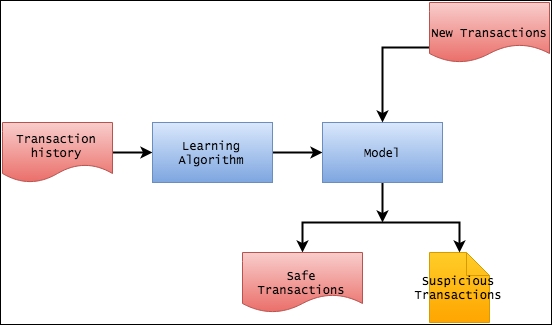
In the previous section, we have already cleansed the transaction history file to make it suitable for the machine learning algorithm. For building the model, we will use Apache Spark.
Introducing Apache Spark
Apache Spark is an open source, big data processing framework, developed in 2009 in UC Berkeley's AMPLab. It has been developed around the goals of delivering speed, ease of use, and sophisticated analytics.
It was open sourced in 2010 as an Apache project and it has now become one of the most active projects among Apache Software Foundation projects. The...





