























































Slimming the classifier
It is always worth looking at the actual contributions of the individual features. For logistic regression, we can directly take the learned coefficients (clf.coef_) to get an impression of the features' impact:
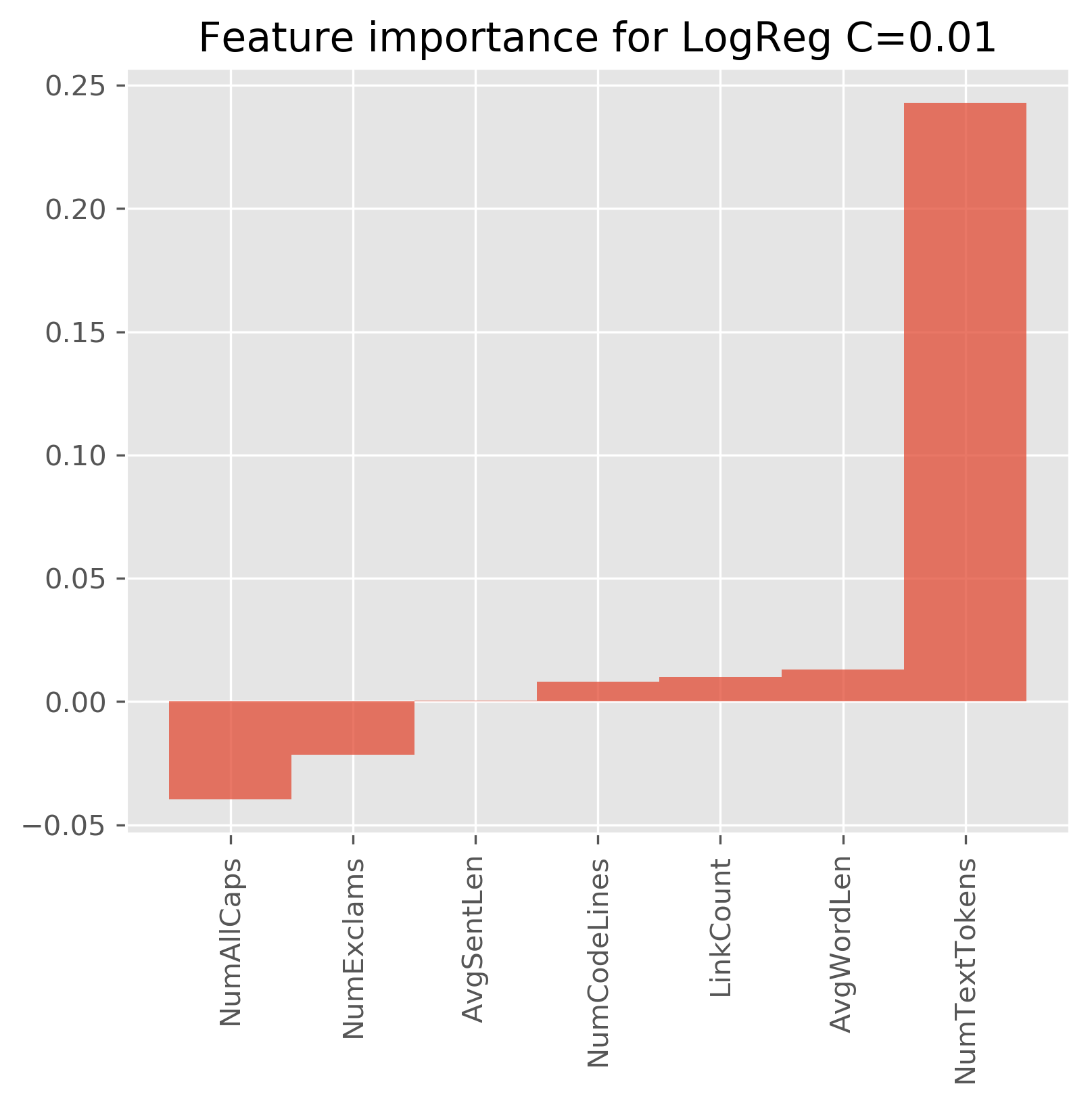
We see that NumCodeLines, LinkCount, AvgWordLen, and NumTextTokens have the highest positive impact on determining whether a post is a good one, while AvgWordLen, LinkCount, and NumCodeLines have a say in that as well, but much less so. This means that being more verbose will more likely result in a classification as a good answer.
On the other side, we have NumAllCaps and NumExclams have negative weights one. That means that the more an answer is shouting, the less likely it will be received well.
Then we have the AvgSentLen feature, which does not seem to help much in detecting a good answer. We could easily drop that feature and retain. However, just from the same classification performance magnitude of the coefficients, we cannot immediately derive the feature...

















