























































Using a skew join
In this recipe, you will learn how to use a skew join in Hive.
A skew join is used when there is a table with skew data in the joining column. A skew table is a table that is having values that are present in large numbers in the table compared to other data. Skew data is stored in a separate file while the rest of the data is stored in a separate file.
If there is a need to perform a join on a column of a table that is appearing quite often in the table, the data for that particular column will go to a single reducer, which will become a bottleneck while performing the join. To reduce this, a skew join is used.
The following parameter needs to be set for a skew join:
set hive.optimize.skewjoin=true; set hive.skewjoin.key=100000;
How to do it…
Run the following command to use a bucket sort merge map join in Hive:
SELECT a.* FROM Sales a JOIN Sales_orc b ON a.id = b.id;
How it works…
Let us suppose that there are two tables, Sales and Sales_orc, as shown next:
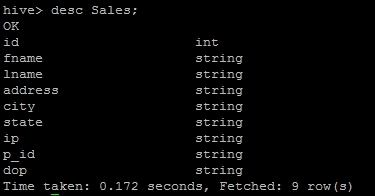
The Sales table...





