























































A parallel solution with Akka
Before approaching the problem of parallelizing our crawler, let's discuss our strategy of how we are going to approach it.
Strategy
We are going to model our problem of creating the actors' system with a tree of actors. This is because the task itself naturally forms a tree.
We have already discussed how all the links and pages on the internet comprise a graph. However, we have also discussed, in our example, two things that are not desirable when processing and traversing this graph—cycles and repetitions of work. So, if we have visited a certain node, we are not going to visit it anymore.
This means that our graph becomes a tree on processing time. This means you cannot get to a parent node from a child node when descending from a child node. This tree may look as follows:
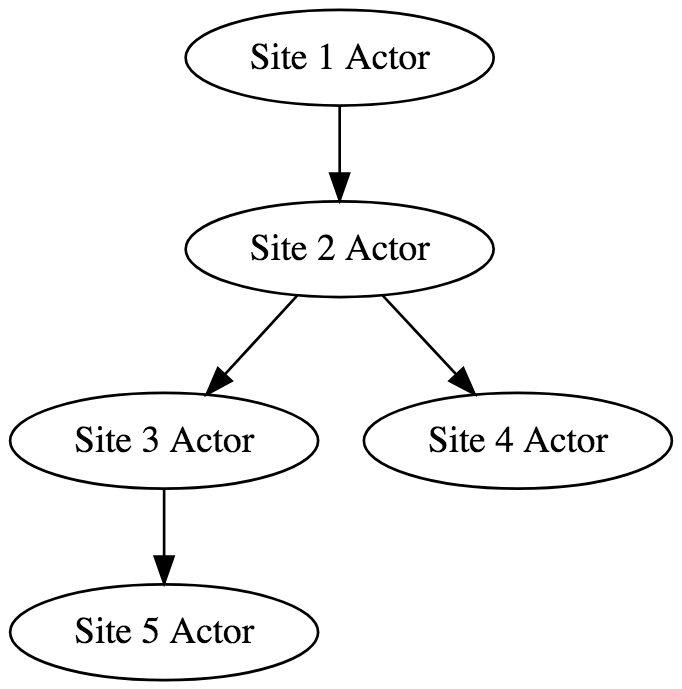
We are going to communicate with the root-level node. So basically, we will send this node a link that we are going to start crawling from, and afterward, this actor is going to crawl...











