























































Exploring fault tolerance
Since we are exploring self-healing (not self-adaptation), there's no need to deploy all the stacks we used thus far. A single service will be enough to explore what happens when a node goes down. Our cluster, formed out of t2.micro instances, would not support much more anyways.
docker service create --name test \
--replicas 10 alpine sleep 1000000We created a service with ten replicas. Let's confirm that they are spread across the three nodes of the cluster:
docker service ps testThe output is as follows (IDs are removed for brevity):
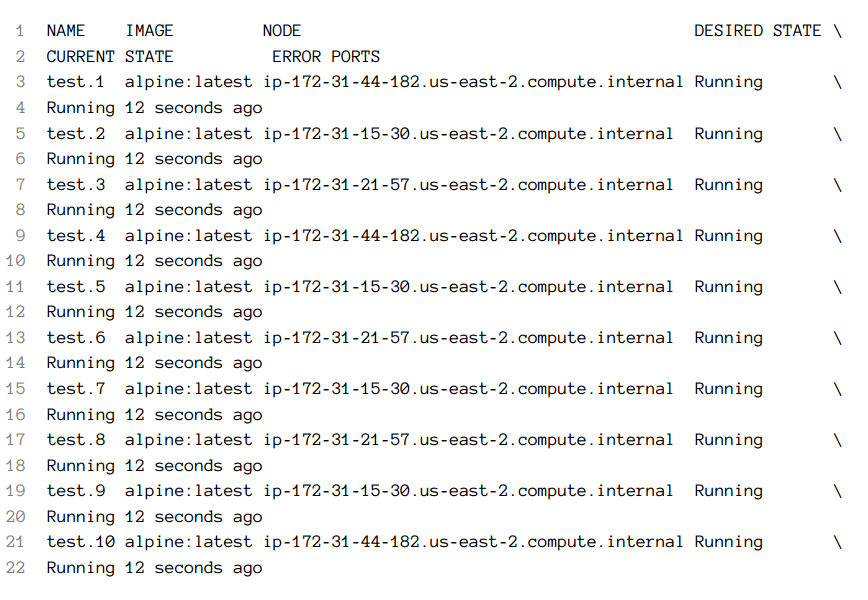
Let's exit the cluster before we move onto a discussion how to simulate a failure of a node.
exitWe'll simulate failure of an instance by terminating it. We'll do that by executing aws ec2 terminate-instances command that requires --instance-ids argument. So, the first line of business is to figure out how to find ID of one of the nodes.
We already saw that we could use aws ec2 describe-instances command to get information about...














