























































Introduction
Of all the machine learning algorithms we have considered thus far, none have considered data as a sequence. To take sequence data into account, we extend neural networks that store outputs from prior iterations. This type of neural network is called an RNN. Consider the fully connected network formulation:

Here, the weights are given by A multiplied by the input layer, x, and then run through an activation function,
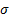
, which gives the output layer, y.
If we have a sequence of input data,

, we can adapt the fully connected layer to take prior inputs into account, as follows:

On top of this recurrent iteration to get the next input, we want to get the probability distribution output, as follows:

Once we have a full sequence output,

, we can consider the target as a number or category by just considering the last output. See the following diagram for how a general architecture might work:

Figure 1: To predict a single number, or a category, we take a sequence of inputs (tokens) and...



















