























































Describing why you should use SAP HANA
This section explains why should we use SAP HANA even though there are many databases on the market.
Getting ready
SAP HANA is a real-time applications platform that provides a multipurpose, in-memory appliance. Decision makers in the organization can gain instant insight into business operations. As all the data available can be analyzed, they can react to the business conditions rapidly to make decisions. The following are the advantages of SAP HANA:
Real Time: One can access the most granular information from both SAP and non-SAP sources within moments of it changing.
Applications: SAP HANA is the future for the entire SAP portfolio of products and solutions, unlocking new insights, predicting issues before they occur, and allowing you to plan for scenarios at the speed of thought.
Platform: SAP HANA is fundamentally different from anything else on the market. The SAP HANA platform will power current products, such as Business Warehouse, and new trends, such as mobility, for which fast analysis and advanced computation is required.
How it works…
Now it's time to look at the differences between traditional and SAP HANA databases.
Traditional versus in-memory
The following table distinguishes between the approaches of traditional and SAP HANA databases toward different scenarios:
|
Key features for comparison |
Traditional approach |
Next generation approach |
|---|---|---|
|
Volume of data |
Row store, compression (disk-based). Data duplication through aggregates, caching, and compression. |
Column store and compression (in-memory-based) addressed by keeping all data in-memory. No data duplication using non-materialized views (no aggregates). |
|
Information latency |
ETL leads to batch loading and the delayed availability of information. Additional delay in latency by rolling up aggregates and caching. |
Addressed by replication server Non-materialized views (no aggregates required). Quick performance on all the data (not relying on in-memory caches). |
|
Computation speeds |
Addressed by row store and caching the data to memory. |
Addressed by column storage and the full in-memory dataset. The calculation happens in-memory, that is, in the database tier instead of the application tier. |
|
Flexibility and robustness |
Disk-based solutions provide limited flexibility (changing data models or re-aligning hierarchies requires changes to aggregates, caches, and so on). |
HANA allows us to change our data model anytime as changes occur in-memory and is not limited by disk persistence first. |
|
Data governance |
Duplicate versions of data in a layered, scalable architecture involve costly reconciliation activities. |
Provides a single version of the truth. |
|
Application platform |
Only for analytical use cases (not transactional). |
Targets applications that combine both OLAP and OLTP. |
There's more…
Let us also see how data marts exist in Business Intelligence today. We initially store the data in a staging area. Then, we store the same data redundantly in different layers. Data in each layer differs by the way it is stored such as operational datastores, after applying business logics, and aggregated data. In this case, data has to hop through multiple layers. So, it takes a lot of time to reach end users for decision-making. The data is useless when it is not available in time for decision-making.
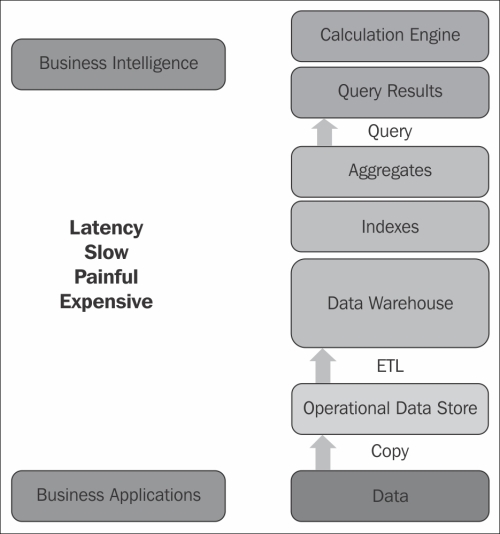
Let's go through a detailed analysis of this scenario. Several layers exist between operational datastores and the application layers, in which reports are executed by the users. Based on these reports, decisions are made to run the business. All the middle-level layers, such as warehouses, data marts, cubes, and universes, are involved only in data copying and management processes. Data has to hop through all these layers to reach reports.
There are exponential changes in terms of memory, but not in terms of disk access. Disc access speed is almost the same as it was in the past as there are aerodynamic limits—disks would fly off the spindle at very high speeds.
Hence, data storage in the main memory helped reduce the cost of disk access. But the cost involved in storage memory is too high. With time, the cost of memory came down, making memory cheaper than in the past. So, databases are designed in such a way that all the data resides in the main memory.
Why choose SAP HANA only to reduce the costs involved with all the layers? As an in-memory database that supports the real-time processing of data, data is aggregated and processed in the memory itself, thereby getting the results at an amazing speed. Results can be shown on-the-fly so that middle-level management related to IT can be replaced for fulfilling the new requests from users.
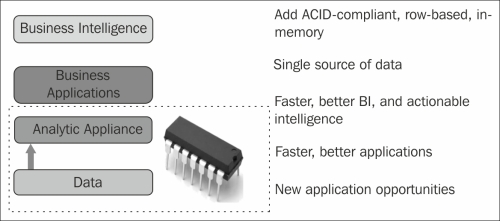
See also
The ACID properties in DBMS are explained well in this presentation available at http://www.google.co.in/url?sa=t&rct=j&q=&esrc=s&frm=1&source=web&cd=1&ved=0CCgQFjAA&url=http%3A%2F%2Fieor.berkeley.edu%2F~goldberg%2Fcourses%2FF04%2F215%2F215-Database-Recovery.ppt&ei=5_6oUqPUJMv9rAfumoCADg&usg=AFQjCNGDh-fEkdc2B9jNGSCqK4sX-ZEVMw
Information on data marts in Business Intelligence is available at http://www.yellowfinbi.com/YFForum-Whats-a-Data-Mart-?thread=92098




