























































An example dynamic web page
Let's look at an example dynamic web page. The example website has a search form, which is available at http://example.webscraping.com/search, which is used to locate countries. Let's say we want to find all the countries that begin with the letter A:
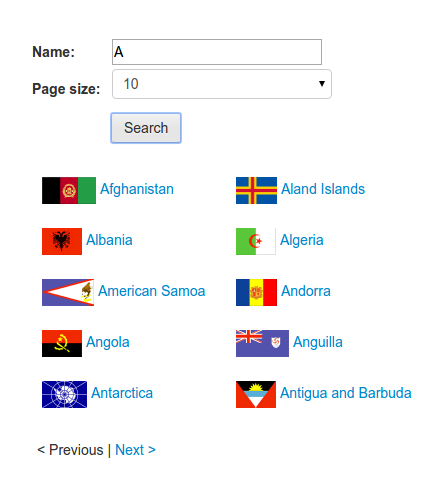
If we right-click on these results to inspect them with our browser tools (as covered in Chapter 2, Scraping the Data), we would find the results are stored within a div element with ID "results":
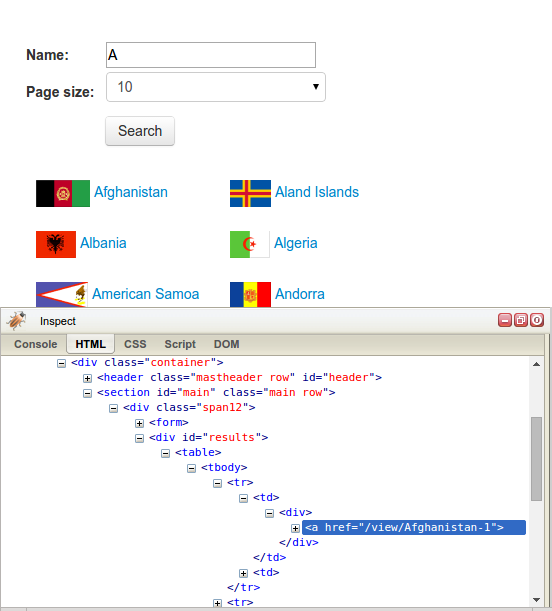
Let's try to extract these results using the lxml module, which was also covered in Chapter 2, Scraping the Data, and the Downloader class from Chapter 3, Caching Downloads:
>>> from lxml.html import fromstring >>> from downloader import Downloader >>> D = Downloader() >>> html = D('http://example.webscraping.com/search') >>> tree = fromstring(html) >>> tree.cssselect('div#results a') []
The example scraper here has failed to extract results. Examining the source code...














