























































Temporal difference methods
Temporal difference (TD) is a class of model-free RL methods. On the one hand, they can learn from the agent's experience, such as MC. On the other hand, they can estimate state values based on the values of other states, such as DP. As usual, we'll explore the policy evaluation and improvement tasks.
Policy evaluation
TD methods rely on their experience for policy evaluation. But unlike MC, they don't have to wait until the end of an episode. Instead, they can update the action-value function after each step of the episode. In its most basic form, a TD algorithm uses the following formula to perform a state-value update:
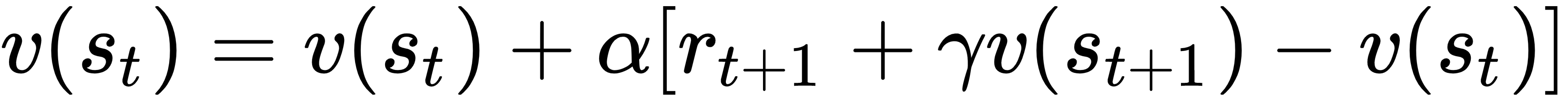
Where α is called step size (learning rate) and it's in the range of [0, 1]. Let's analyze this equation. We're going to update the value of the st state and we're following a policy, π, that has led the agent to transition from the st state to the st+1 state. During the transition, the agent has received a reward, rt+1. Think of
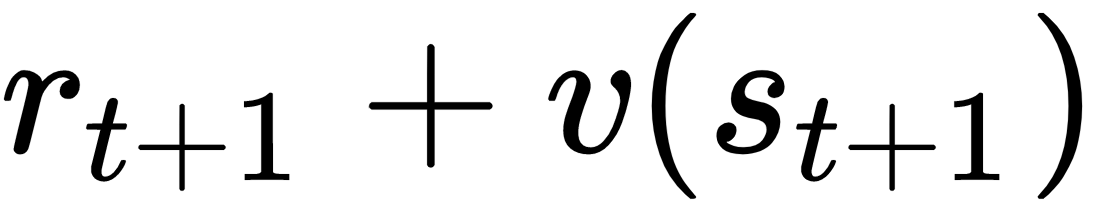
as the label...

















