























































Flume
Flume is a reliable, available and distributed service to efficiently collect, aggregate, and transport large amounts of log data. It has a flexible and simple architecture that is based on streaming data flows. The current version of Apache Flume is 1.7.0, which was released in October 2016.
Apache Flume architecture
The following diagram depicts the architecture of Apache Flume:
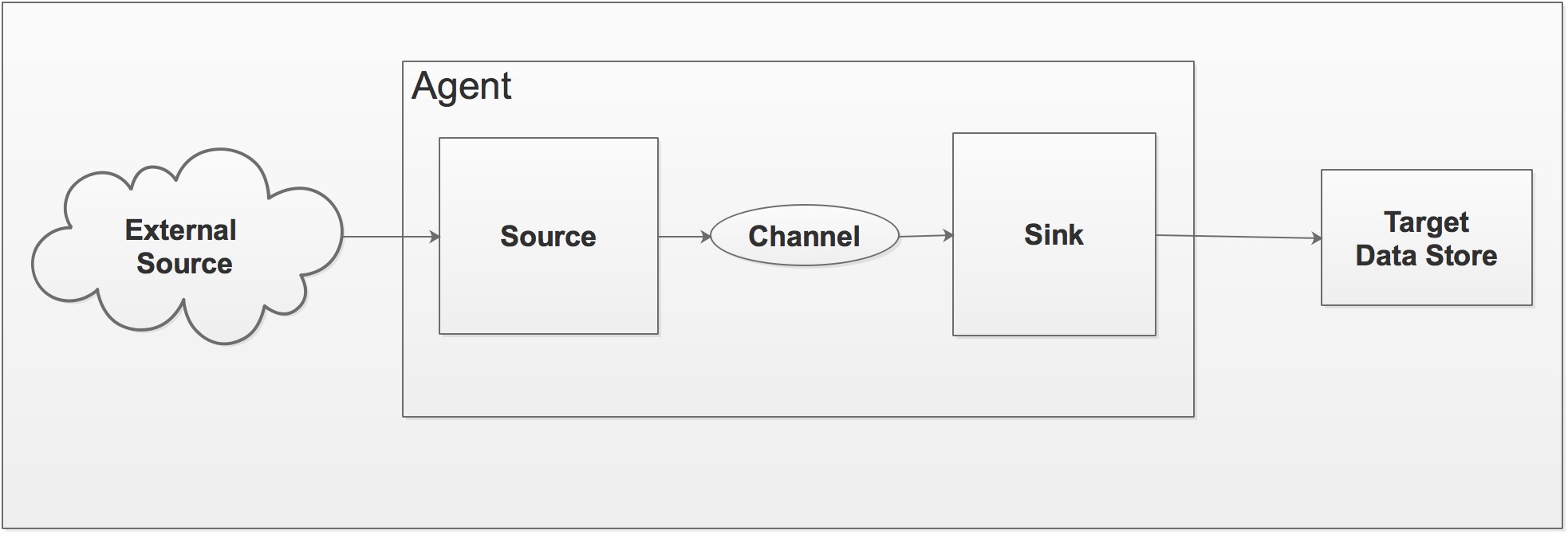
Let's take a closer look at the components of the Apache Flume architecture:
- Event: An event is a byte payload with optional string headers. It represents the unit of data that Flume can carry from its source to destination.
- Flow: The transport of events from source to destination is considered a data flow, or just flow.
- Agent: It is an independent process that hosts the components of Flume, such as sources, channels, and sinks. It thus has the ability to receive, store, and forward events to its next-hop destination.
- Source: The source is an interface implementation. It has the ability to consume events that are...

















