























































High-availability best practices
Building reliable and highly available distributed systems is an important endeavor. In this section, we will check some of the best practices that enable a Kubernetes-based system to function reliably and be available in the face of various failure categories.
Creating highly available clusters
To create a highly available Kubernetes cluster, the master components must be redundant. This means that etcd must be deployed as a cluster (typically across three or five nodes) and the Kubernetes API server must be redundant. Auxiliary cluster management services, such as Heapster's storage, may be deployed redundantly too, if necessary. The following diagram depicts a typical reliable and highly available Kubernetes cluster. There are several load-balanced master nodes, each one containing whole master components as well as an etcd component:
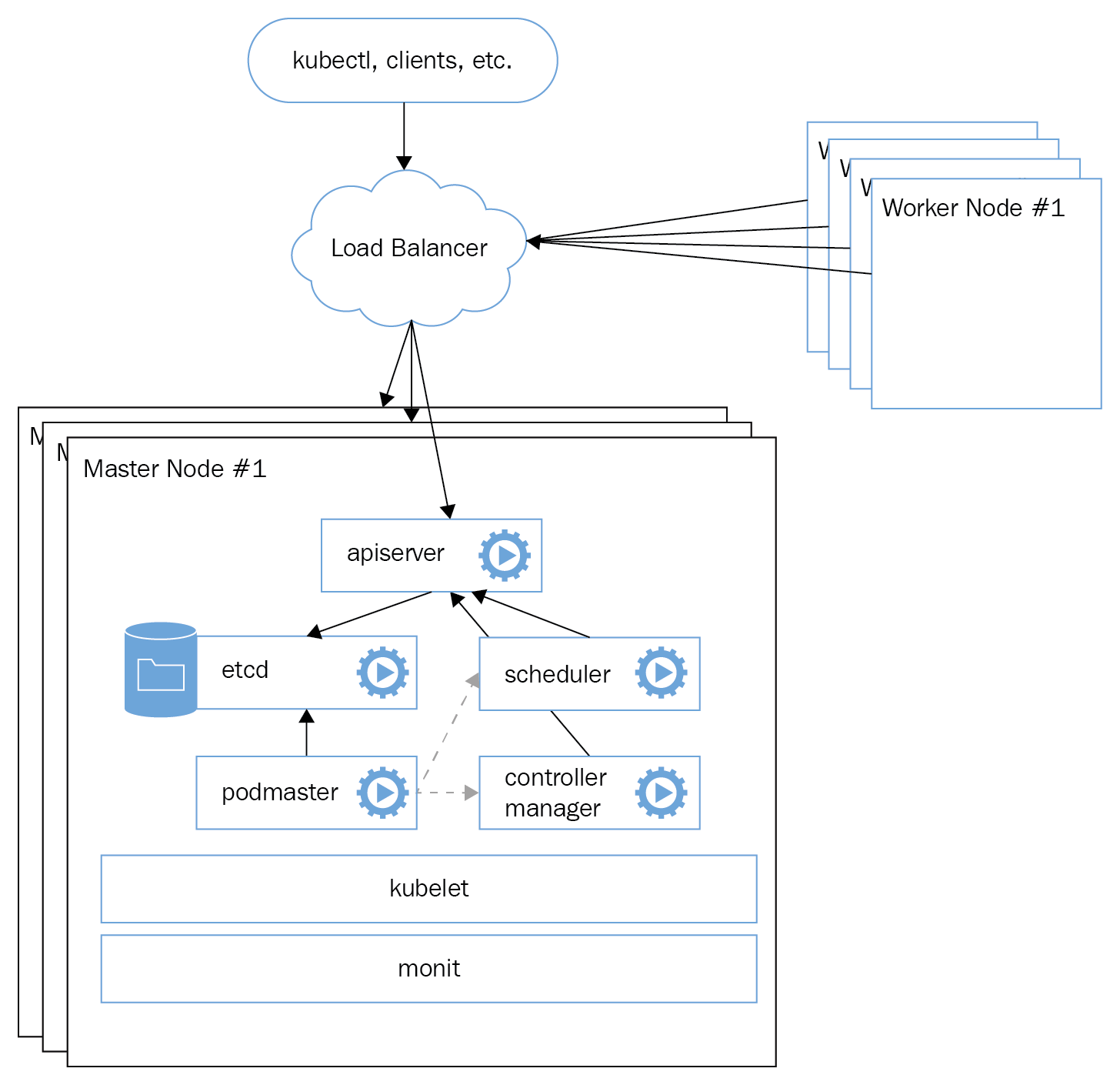
This is not the only way to configure highly available clusters. You may prefer, for example, to deploy a standalone etcd...














