























































Chapter 9. Spider – Sharding Your Data
Spider is a specific engine made for MySQL/MariaDB. It has been integrated in MariaDB 10 which makes it one of the new and major features. It's a specific storage engine dedicated to shard data across several MariaDB servers.
It should act as a proxy to be able to work properly:
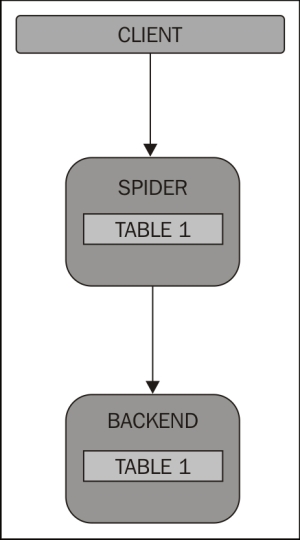
You can see in the preceding diagram that a client is talking directly to Spider to get access to its backend table content.
However, the goal of Spider is to shard your data across multiple backend servers, as illustrated in the following diagram:
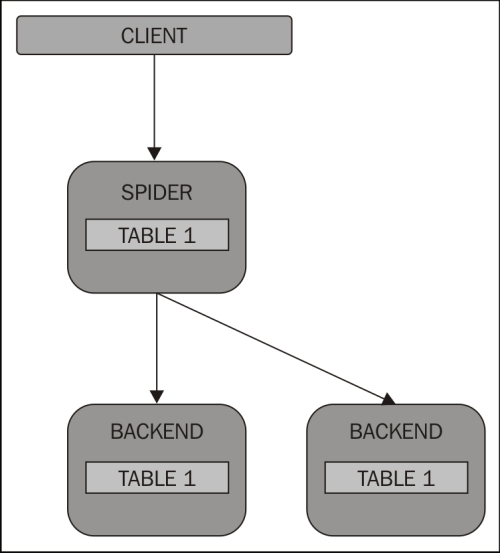
Sharding will split your data on several servers to speed up read and write queries. However, in this case, we need to replicate our shards to avoid data loss, as shown in the following diagram:
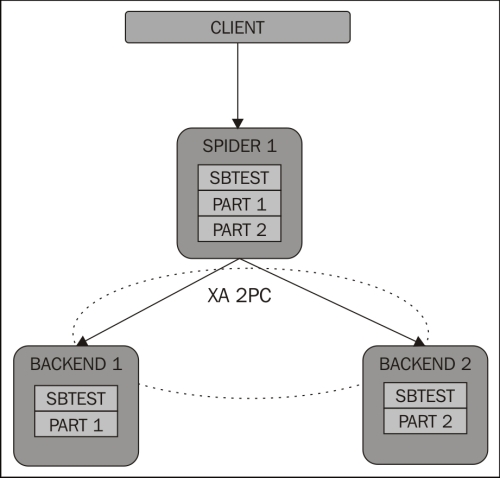
Spider monitors itself to produce SQL errors when one of the backend tables is not available. As you can see, there are three Spider servers here to avoid a split-brain (classical cluster-consensus).
Note
When Spider creates a table, the table links...


