























































Spark GraphX
GraphX is a layer over Spark, thus it leverages all the interesting things about Spark-distributed processing, the algorithms, the versioned computation graph, and so forth. Interestingly, a couple of ML algorithms are written using GraphX APIs. Now refer to the following figure:
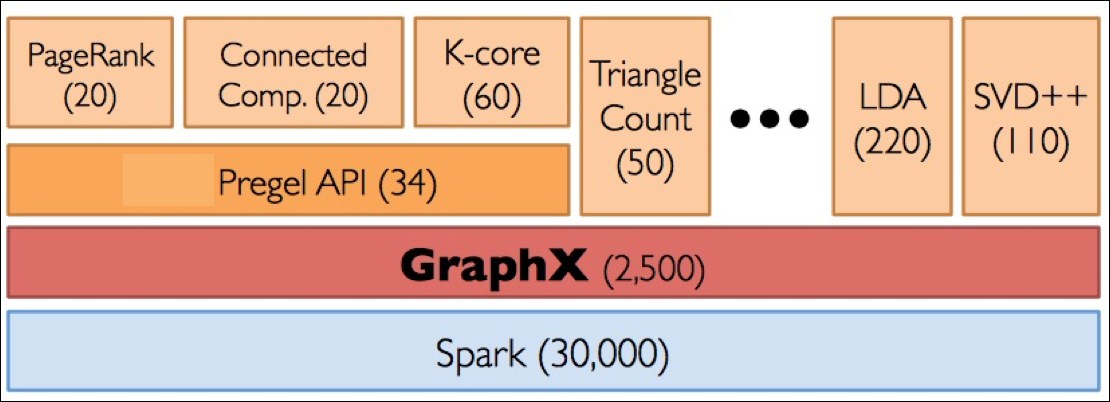
This diagram shows the layers and the relationships between GraphX, Spark, and the algorithms. GraphX is truly a distributed graph-processing component at scale with powerful partitioning mechanisms, and of course, the in-memory representation that makes iterative processing faster than normal. The programming is much more succinct and very powerful. I went back to the source code and counted the lines of implementations of graph-related algorithms. PageRank is composed of 60 lines using the aggregateMessages API (which, as you will see later, is a very powerful abstraction) and 60 lines for runUntilConvergence using the Pregel API. The triangle count is 50 lines of code, and SVD++ is 150 lines of...





