In this article by Asif Abbasi author of the book Learning Apache Spark 2.0, we will understand Spark RDD along with that we will learn, how to construct RDDs, Operations on RDDs, Passing functions to Spark in Scala, Java, and Python and Transformations such as map, filter, flatMap, and sample.
(For more resources related to this topic, see here.)
What is an RDD?
What’s in a name might be true for a rose, but perhaps not for an Resilient Distributed Datasets (RDD), and in essence describes what an RDD is.
They are basically datasets, which are distributed across a cluster (remember Spark framework is inherently based on an MPP architecture), and provide resilience (automatic failover) by nature.
Before we go into any further detail, let’s try to understand this a little bit, and again we are trying to be as abstract as possible. Let us assume that you have a sensor data from aircraft sensors and you want to analyze the data irrespective of its size and locality. For example, an Airbus A350 has roughly 6000 sensors across the entire plane and generates 2.5 TB data per day, while the newer model expected to launch in 2020 will generate roughly 7.5 TB per day. From a data engineering point of view, it might be important to understand the data pipeline, but from an analyst and a data scientist point of view, your major concern is to analyze the data irrespective of the size and number of nodes across which it has been stored. This is where the neatness of the RDD concept comes into play, where the sensor data can be encapsulated as an RDD concept, and any transformation/action that you perform on the RDD applies across the entire dataset. Six month's worth of dataset for an A350 would be approximately 450 TBs of data, and would need to sit across multiple machines.
For the sake of discussion, we assume that you are working on a cluster of four worker machines. Your data would be partitioned across the workers as follows:

Figure 2-1: RDD split across a cluster
The figure basically explains that an RDD is a distributed collection of the data, and the framework distributes the data across the cluster. Data distribution across a set of machines brings its own set of nuisances including recovering from node failures. RDD’s are resilient as they can be recomputed from the RDD lineage graph, which is basically a graph of the entire parent RDDs of the RDD. In addition to the resilience, distribution, and representing a data set, an RDD has various other distinguishing qualities:
- In Memory: An RDD is a memory resident collection of objects. We’ll look at options where an RDD can be stored in memory, on disk, or both. However, the execution speed of Spark stems from the fact that the data is in memory, and is not fetched from disk for each operation.
- Partitioned: A partition is a division of a logical dataset or constituent elements into independent parts. Partitioning is a defacto performance optimization technique in distributed systems to achieve minimal network traffic, a killer for high performance workloads. The objective of partitioning in key-value oriented data is to collocate similar range of keys and in effect minimize shuffling. Data inside RDD is split into partitions and across various nodes of the cluster.
- Typed: Data in an RDD is strongly typed. When you create an RDD, all the elements are typed depending on the data type.
- Lazy evaluation: The transformations in Spark are lazy, which means data inside RDD is not available until you perform an action. You can, however, make the data available at any time using a count() action on the RDD. We’ll discuss this later and the benefits associated with it.
- Immutable: An RDD once created cannot be changed. It can, however, be transformed into a new RDD by performing a set of transformations on it.
- Parallel: An RDD is operated on in parallel. Since the data is spread across a cluster in various partitions, each partition is operated on in parallel.
- Cacheable: Since RDD’s are lazily evaluated, any action on an RDD will cause the RDD to revaluate all transformations that led to the creation of RDD. This is generally not a desirable behavior on large datasets, and hence Spark allows the option to persist the data on memory or disk.
A typical Spark program flow with an RDD includes:
- Creation of an RDD from a data source.
- A set of transformations, for example, filter, map, join, and so on.
- Persisting the RDD to avoid re-execution.
- Calling actions on the RDD to start performing parallel operations across the cluster.
This is depicted in the following figure:
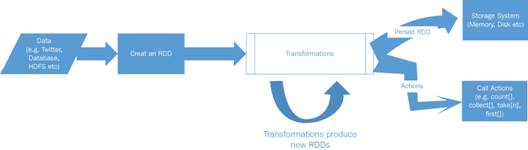
Figure 2-2: Typical Spark RDD flow
Operations on RDD
Two major operation types can be performed on an RDD. They are called:
Transformations
Transformations are operations that create a new dataset, as RDDs are immutable. They are used to transform data from one to another, which could result in amplification of the data, reduction of the data, or a totally different shape altogether. These operations do not return any value back to the driver program, and hence lazily evaluated, which is one of the main benefits of Spark.
An example of a transformation would be a map function that will pass through each element of the RDD and return a totally new RDD representing the results of application of the function on the original dataset.
Actions
Actions are operations that return a value to the driver program. As previously discussed, all transformations in Spark are lazy, which essentially means that Spark remembers all the transformations carried out on an RDD, and applies them in the most optimal fashion when an action is called. For example, you might have a 1 TB dataset, which you pass through a set of map functions by applying various transformations. Finally, you apply the reduce action on the dataset. Apache Spark will return only a final dataset, which might be few MBs rather than the entire 1 TB dataset of mapped intermediate result.
You should, however, remember to persist intermediate results otherwise Spark will recompute the entire RDD graph each time an Action is called. The persist() method on an RDD should help you avoid recomputation and saving intermediate results. We’ll look at this in more detail later.
Let’s illustrate the work of transformations and actions by a simple example. In this specific example, we’ll be using flatmap() transformations and a count action. We’ll use the README.md file from the local filesystem as an example. We’ll give a line-by-line explanation of the Scala example, and then provide code for Python and Java. As always, you must try this example with your own piece of text and investigate the results:
//Loading the README.md file
val dataFile = sc.textFile(“README.md”)
Now that the data has been loaded, we’ll need to run a transformation. Since we know that each line of the text is loaded as a separate element, we’ll need to run a flatMap transformation and separate out individual words as separate elements, for which we’ll use the split function and use space as a delimiter:
//Separate out a list of words from individual RDD elements
val words = dataFile.flatMap(line => line.split(“ “))
Remember that until this point, while you seem to have applied a transformation function, nothing has been executed and all the transformations have been added to the logical plan. Also note that the transformation function returns a new RDD. We can then call the count() action on the words RDD, to perform the computation, which then results in fetching of data from the file to create an RDD, before applying the transformation function specified. You might note that we have actually passed a function to Spark:
//Separate out a list of words from individual RDD elements
Words.count()
Upon calling the count() action the RDD is evaluated, and the results are sent back to the driver program. This is very neat and especially useful during big data applications.
If you are Python savvy, you may want to run the following code in PySpark. You should note that lambda functions are passed to the Spark framework:
//Loading data file, applying transformations and action
dataFile = sc.textFile("README.md")
words = dataFile.flatMap(lambda line: line.split(" "))
words.count()
Programming the same functionality in Java is also quite straight forward and will look pretty similar to the program in Scala:
JavaRDD<String> lines = sc.textFile("README.md");
JavaRDD<String> words = lines.map(line -> line.split(“ “));
int wordCount = words.count();
This might look like a simple program, but behind the scenes it is taking the line.split(“ ”) function and applying it to all the partitions in the cluster in parallel. The framework provides this simplicity and does all the background work of coordination to schedule it across the cluster, and get the results back.
Passing functions to Spark (Scala)
As you have seen in the previous example, passing functions is a critical functionality provided by Spark. From a user’s point of view you would pass the function in your driver program, and Spark would figure out the location of the data partitions across the cluster memory, running it in parallel. The exact syntax of passing functions differs by the programming language. Since Spark has been written in Scala, we’ll discuss Scala first.
In Scala, the recommended ways to pass functions to the Spark framework are as follows:
- Anonymous functions
- Static singleton methods
Anonymous functions
Anonymous functions are used for short pieces of code. They are also referred to as lambda expressions, and are a cool and elegant feature of the programming language. The reason they are called anonymous functions is because you can give any name to the input argument and the result would be the same.
For example, the following code examples would produce the same output:
val words = dataFile.map(line => line.split(“ “))
val words = dataFile.map(anyline => anyline.split(“ “))
val words = dataFile.map(_.split(“ “))

Figure 2-11: Passing anonymous functions to Spark in Scala
Static singleton functions
While anonymous functions are really helpful for short snippets of code, they are not very helpful when you want to request the framework for a complex data manipulation. Static singleton functions come to the rescue with their own nuances, which we will discuss in this section.
In software engineering, the Singleton pattern is a design pattern that restricts instantiation of a class to one object. This is useful when exactly one object is needed to coordinate actions across the system.
Static methods belong to the class and not an instance of it. They usually take input from the parameters, perform actions on it, and return the result.

Figure 2-12: Passing static singleton functions to Spark in Scala
Static singleton is the preferred way to pass functions, as technically you can create a class and call a method in the class instance. For example:
class UtilFunctions{
def split(inputParam: String): Array[String] =
{inputParam.split(“ “)}
def operate(rdd: RDD[String]): RDD[String] ={ rdd.map(split)}
}
You can send a method in a class, but that has performance implications as the entire object would be sent along the method.
Passing functions to Spark (Java)
In Java, to create a function you will have to implement the interfaces available in the org.apache.spark.api.java function package. There are two popular ways to create such functions:
- Implement the interface in your own class, and pass the instance to Spark.
- Starting Java 8, you can use lambda expressions to pass off the functions to the Spark framework.
Let’s reimplement the preceding word count examples in Java:

Figure 2-13: Code example of Java implementation of word count (inline functions)
If you belong to a group of programmers who feel that writing inline functions makes the code complex and unreadable (a lot of people do agree to that assertion), you may want to create separate functions and call them as follows:

Figure 2-14: Code example of Java implementation of word count
Passing functions to Spark (Python)
Python provides a simple way to pass functions to Spark. The Spark programming guide available at spark.apache.org suggests there are three recommended ways to do this:
- Lambda expressions: The ideal way for short functions that can be written inside a single expression
- Local defs inside the function calling into Spark for longer code
- Top-level functions in a module
While we have already looked at the lambda functions in some of the previous examples, let’s look at local definitions of the functions. Our example stays the same, which is we are trying to count the total number of words in a text file in Spark:
def splitter(lineOfText):
words = lineOfText.split(" ")
return len(words)
def aggregate(numWordsLine1, numWordsLineNext):
totalWords = numWordsLine1 + numWordsLineNext
return totalWords
Let’s see the working code example:

Figure 2-15: Code example of Python word count (local definition of functions)
Here’s another way to implement this by defining the functions as a part of a UtilFunctions class, and referencing them within your map and reduce functions:

Figure 2-16: Code example of Python word count (Utility class)
You may want to be a bit cheeky here and try to add a countWords() to the UtilFunctions, so that it takes an RDD as input, and returns the total number of words. This method has potential performance implications as the whole object will need to be sent to the cluster. Let’s see how this can be implemented and the results in the following screenshot:

Figure 2-17: Code example of Python word count (Utility class - 2)
This can be avoided by making a copy of the referenced data field in a local object, rather than accessing it externally.
Now that we have had a look at how to pass functions to Spark, and have already looked at some of the transformations and actions in the previous examples, including map, flatMap, and reduce, let’s look at the most common transformations and actions used in Spark. The list is not exhaustive, and you can find more examples in the Apache Spark documentation in the programming guide. If you would like to get a comprehensive list of all the available functions, you might want to check the following API docs:
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
Renews at £15.99/month. Cancel anytime
|
|
RDD
|
PairRDD
|
|
Scala
|
http://bit.ly/2bfyoTo
|
http://bit.ly/2bfzgah
|
|
Python
|
http://bit.ly/2bfyURl
|
N/A
|
|
Java
|
http://bit.ly/2bfyRov
|
http://bit.ly/2bfyOsH
|
|
R
|
http://bit.ly/2bfyrOZ
|
N/A
|
Table 2.1 – RDD and PairRDD API references
Transformations
The following table shows the most common transformations:
|
map(func)
|
coalesce(numPartitions)
|
|
filter(func)
|
repartition(numPartitions)
|
|
flatMap(func)
|
repartitionAndSortWithinPartitions(partitioner)
|
|
mapPartitions(func)
|
join(otherDataset, [numTasks])
|
|
mapPartitionsWithIndex(func)
|
cogroup(otherDataset, [numTasks])
|
|
sample(withReplacement, fraction, seed)
|
cartesian(otherDataset)
|
Map(func)
The map transformation is the most commonly used and the simplest of transformations on an RDD. The map transformation applies the function passed in the arguments to each of the elements of the source RDD. In the previous examples, we have seen the usage of map() transformation where we have passed the split() function to the input RDD.

Figure 2-18: Operation of a map() function
We’ll not give examples of map() functions as we have already seen plenty of examples of map functions previously.
Filter (func)
Filter, as the name implies, filters the input RDD, and creates a new dataset that satisfies the predicate passed as arguments.
Example 2-1: Scala filtering example:
val dataFile = sc.textFile(“README.md”)
val linesWithApache = dataFile.filter(line => line.contains(“Apache”))
Example 2-2: Python filtering example:
dataFile = sc.textFile(“README.md”)
linesWithApache = dataFile.filter(lambda line: “Apache” in line)
Example 2-3: Java filtering example:
JavaRDD<String> dataFile = sc.textFile(“README.md”)
JavaRDD<String> linesWithApache = dataFile.filter(line -> line.contains(“Apache”));
flatMap(func)
The flatMap transformation is similar to map, but it offers a bit more flexibility. From the perspective of similarity to a map function, it operates on all the elements of the RDD, but the flexibility stems from its ability to handle functions that return a sequence rather than a single item. As you saw in the preceding examples, we had used flatMap to flatten the result of the split(“”) function, which returns a flattened structure rather than an RDD of string arrays.

Figure 2-19: Operational details of the flatMap() transformation
Let’s look at the flatMap example in Scala.
Example 2-4: The flatmap() example in Scala:
val favMovies = sc.parallelize(List("Pulp Fiction","Requiem for a dream","A clockwork Orange"));
movies.flatMap(movieTitle=>movieTitle.split(" ")).collect()
A flatMap in Python API would produce similar results.
Example 2-5: The flatmap() example in Python:
movies = sc.parallelize(["Pulp Fiction","Requiem for a dream","A clockwork Orange"])
movies.flatMap(lambda movieTitle: movieTitle.split(" ")).collect()
The flatMap example in Java is a bit long-winded, but it essentially produces the same results.
Example 2-6: The flatmap() example in Java:
JavaRDD<String> movies = sc.parallelize
(Arrays.asList("Pulp Fiction","Requiem for a dream"
,"A clockwork Orange")
);
JavaRDD<String> movieName = movies.flatMap(
new FlatMapFunction<String,String>(){
public Iterator<String> call(String movie){
return Arrays.asList(movie.split(" "))
.iterator();
}
}
);
Sample(withReplacement, fraction, seed)
Sampling is an important component of any data analysis and it can have a significant impact on the quality of your results/findings. Spark provides an easy way to sample RDD’s for your calculations, if you would prefer to quickly test your hypothesis on a subset of data before running it on a full dataset. But here is a quick overview of the parameters that are passed onto the method:
- withReplacement: Is a Boolean (True/False), and it indicates if elements can be sampled multiple times (replaced when sampled out). Sampling with replacement means that the two sample values are independent. In practical terms this means that if we draw two samples with replacement, what we get on the first one doesn’t affect what we get on the second draw, and hence the covariance between the two samples is zero.
If we are sampling without replacement, the two samples aren’t independent. Practically this means what we got on the first draw affects what we get on the second one and hence the covariance between the two isn’t zero.
- fraction: Fraction indicates the expected size of the sample as a fraction of the RDD’s size. The fraction must be between 0 and 1. For example, if you want to draw a 5% sample, you can choose 0.05 as a fraction.
- seed: The seed used for the random number generator.
Let’s look at the sampling example in Scala.
Example 2-7: The sample() example in Scala:
val data = sc.parallelize( List(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20));
data.sample(true,0.1,12345).collect()
The sampling example in Python looks similar to the one in Scala.
Example 2-8: The sample() example in Python:
data = sc.parallelize( [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
data.sample(1,0.1,12345).collect()
In Java, our sampling example returns an RDD of integers.
Example 2-9: The sample() example in Java:
JavaRDD<Integer> nums = sc.parallelize(Arrays.asList( 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20));
nums.sample(true,0.1,12345).collect();
References
Summary
We have gone through the concept of creating an RDD, to manipulating data within the RDD. We’ve looked at the transformations and actions available to an RDD, and walked you through various code examples to explain the differences between transformations and actions
Resources for Article:
Further resources on this subject:

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 South Africa
South Africa
 Thailand
Thailand
 Ukraine
Ukraine
 Switzerland
Switzerland
 Slovakia
Slovakia
 Luxembourg
Luxembourg
 Hungary
Hungary
 Romania
Romania
 Denmark
Denmark
 Ireland
Ireland
 Estonia
Estonia
 Belgium
Belgium
 Italy
Italy
 Finland
Finland
 Cyprus
Cyprus
 Lithuania
Lithuania
 Latvia
Latvia
 Malta
Malta
 Netherlands
Netherlands
 Portugal
Portugal
 Slovenia
Slovenia
 Sweden
Sweden
 Argentina
Argentina
 Colombia
Colombia
 Ecuador
Ecuador
 Indonesia
Indonesia
 Mexico
Mexico
 New Zealand
New Zealand
 Norway
Norway
 South Korea
South Korea
 Taiwan
Taiwan
 Turkey
Turkey
 Czechia
Czechia
 Austria
Austria
 Greece
Greece
 Isle of Man
Isle of Man
 Bulgaria
Bulgaria
 Japan
Japan
 Philippines
Philippines
 Poland
Poland
 Singapore
Singapore
 Egypt
Egypt
 Chile
Chile
 Malaysia
Malaysia













