In this article by David Boike, author of the book Learning NServiceBus Second Edition we will explore the tools that NServiceBus gives us to stare at failure in the face and laugh. We'll discuss error queues, automatic retries, and controlling how those retries occur. We'll also discuss how to deal with messages that may be transient and should not be retried in certain conditions. Lastly, we'll examine the difficulty of web service integrations that do not handle retries cleanly on their own.
(For more resources related to this topic, see here.)
Fault tolerance and transactional processing
In order to understand the fault tolerance we gain from using NServiceBus, let's first consider what happens without it.
Let's order something from a fictional website and watch what might happen to process that order. On our fictional website, we add Batman Begins to our shopping cart and then click on the Checkout button. While our cursor is spinning, the following process is happening:
- Our web request is transmitted to the web server.
- The web application knows it needs to make several database calls, so it creates a new transaction scope.
- Database Call 1 of 3: The shopping cart information is retrieved from the database.
- Database Call 2 of 3: An Order record is inserted.
- Database Call 3 of 3: We attempt to insert OrderLine records, but instead get Error Message: Transaction (Process ID 54) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
- This exception causes the transaction to roll back.
This process is shown in the following diagram:

Ugh! If you're using SQL Server and you've never seen this, you haven't been coding long enough. It never happens during development; there just isn't enough load. It's even possible that this won't occur during load testing. It will likely occur during heavy load at the worst possible time, for example, right after your big launch.
So obviously, we should log the error, right? But then what happens to the order? Well that's gone, and your boss may not be happy about losing that revenue. And what about our user? They will likely get a nasty error message. We won't want to divulge the actual exception message, so they will get something like, "An unknown error has occurred. The system administrator has been notified. Please try again later." However, the likelihood that they want to trust their credit card information to a website that has already blown up in their face once is quite low.
So how can we do better? Here's how this scenario could have happened with NServiceBus:

- The web request is transmitted to the web server.
- We add the shopping cart identifier to an NServiceBus command and send it through the Bus.
- We redirect the user to a new page that displays the receipt, even though the order has not yet been processed.
Elsewhere, an Order service is ready to start processing a new message:
- The service creates a new transaction scope, and receives the message within the transaction.
- Database Call 1 of 3: The shopping cart information is retrieved from the database.
- Database Call 2 of 3: An Order record is inserted.
- Database Call 3 of 3: Deadlock!
- The exception causes the database transaction to roll back.
- The transaction controlling the message also rolls back.
- The order is back in the queue.
This is great news! The message is back in the queue, and by default, NServiceBus will automatically retry this message a few times. Generally, deadlocks are a temporary condition, and simply trying again is all that is needed. After all, the SQL Server exception says Rerun the transaction.
Meanwhile, the user has no idea that there was ever a problem. It will just take a little longer (in the order of milliseconds or seconds) to process the order.
Error queues and replay
Whenever you talk about automatic retries in a messaging environment, you must invariably consider poison messages. A poison message is a message that cannot be immediately resolved by a retry because it will consistently result in an error.
A deadlock is a transient error. We can reasonably expect deadlocks and other transient errors to resolve by themselves without any intervention.
Poison messages, on the other hand, cannot resolve themselves. Sometimes, this is because of an extended outage. At other times, it is purely our fault—an exception we didn't catch or an input condition we didn't foresee.
Automatic retries
If we retry poison messages in perpetuity, they will create a blockage in our incoming queue of messages. They will retry over and over, and valid messages will get stuck behind them, unable to make it through.
For this reason, we must set a reasonable limit on retries, and after failing too many times, poison messages must be removed from the processing queue and stored someplace else.
NServiceBus handles all of this for us. By default, NServiceBus will try to process a message five times, after which it will move the message to an error queue, configured by the MessageForwardingInCaseOfFaultConfig configuration section:
<MessageForwardingInCaseOfFaultConfigErrorQueue="error" />
It is in this error queue that messages will wait for administrative intervention. In fact, you can even specify a different server to collect these messages, which allows you to configure one central point in a system where you watch for and deal with all failures:
<MessageForwardingInCaseOfFaultConfigErrorQueue="error@SERVER" />
As mentioned previously, five failed attempts form the default metric for a failed message, but this is configurable via the TransportConfig configuration section:
<section name="TransportConfig" type="NServiceBus.Config.TransportConfig, NServiceBus.Core" />
...
<TransportConfig MaxRetries="3" />
You could also generate the TransportConfig section using the Add-NServiceBusTransportConfig PowerShell cmdlet.
Keep two things in mind:
- Depending upon how you read it, MaxRetries can be a somewhat confusing name. What it really means is the total number of tries, so a value of 5 will result in the initial attempt plus 4 retries. This has the odd side effect that MaxRetries="0" is the same as MaxRetries="1". In both instances, the message would be attempted once.
- During development, you may want to limit retries to MaxRetries="1" so that a single error doesn't cause a nausea-inducing wall of red that flushes your console window's buffer, leaving you unable to scroll up to see what came before. You can then enable retries in production by deploying the endpoint with a different configuration.
Replaying errors
What happens to those messages unlucky enough to fail so many times that they are unceremoniously dumped in an error queue? "I thought you said that Alfred would never give up on us!" you cry.
As it turns out, this is just a temporary holding pattern that enables the rest of the system to continue functioning, while the errant messages await some sort of intervention, which can be human or automated based on your own business rules. Let's say our message handler divides two numbers from the incoming message, and we forget to account for the possibility that one of those numbers might be zero and that dividing by zero is frowned upon.
At this point, we need to fix the error somehow. Exactly what we do will depend upon your business requirements:
- If the messages were sent in an error, we can fix the code that was sending them. In this case, the messages in the error queue are junk and can be discarded.
- We can check the inputs on the message handler, detect the divide-by-zero condition, and make compensating actions. This may mean returning from the message handler, effectively discarding any divide-by-zero messages that are processed, or it may mean doing new work or sending new messages. In this case, we may want to replay the error messages after we have deployed the new code.
- We may want to fix both the sending and receiving side.
Second-level retries
Automatically retrying error messages and sending repeated errors to an error queue is a pretty good strategy to manage both transient errors, such as deadlocks, and poison messages, such as an unrecoverable exception. However, as it turns out, there is a gray area in between, which is best referred to as semi-transient errors. These include incidents such as a web service being down for a few seconds, or a database being temporarily offline. Even with a SQL Server failover cluster, the failover procedure can take upwards of a minute depending on its size and traffic levels.
During a time like this, the automatic retries will be executed immediately and great hordes of messages might go to the error queue, requiring an administrator to take notice and return them to their source queues. But is this really necessary?
As it turns out, it is not. NServiceBus contains a feature called Second-Level Retries (SLR) that will add additional sets of retries after a wait. By default, the SLR will add three additional retry sessions, with an additional wait of 10 seconds each time.
By contrast, the original set of retries is commonly referred to as First-Level Retries (FLR).
Let's track a message's full path to complete failure, assuming default settings:
- Attempt to process the message five times, then wait for 10 seconds
- Attempt to process the message five times, then wait for 20 seconds
- Attempt to process the message five times, then wait for 30 seconds
- Attempt to process the message five times, and then send the message to the error queue
Remember that by using five retries, NServiceBus attempts to process the message five times on every pass.
Using second-level retries, almost every message should be able to be processed unless it is definitely a poison message that can never be successfully processed.
Unlock access to the largest independent learning library in Tech for FREE!
Get unlimited access to 7500+ expert-authored eBooks and video courses covering every tech area you can think of.
Renews at €14.99/month. Cancel anytime
Be warned, however, that using SLR has its downsides too. The first is ignorance of transient errors. If an error never makes it to an error queue and we never manually check out the error logs, there's a chance we might miss it completely. For this reason, it is smart to always keep an eye on error logs. A random deadlock now and then is not a big deal, but if they happen all the time, it is probably still worth some work to improve the code so that the deadlock is not as frequent.
An additional risk lies in the time to process a true poison message through all the retry levels. Not accounting for any time taken to process the message itself 20 times or to wait for other messages in the queue, the use of second-level retries with the default settings results in an entire minute of waiting before you see the message in an error queue. If your business stakeholders require the message to either succeed or fail in 30 seconds, then you cannot possibly meet those requirements.
Due to the asynchronous nature of messaging, we should be careful never to assume that messages in a distributed system will arrive in any particular order. However, it is still good to note that the concept of retries exacerbates this problem. If Message A and then Message B are sent in order, and Message B succeeds immediately but Message A has to wait in an error queue for awhile, then they will most certainly be processed out of order.
Luckily, second-level retries are completely configurable. The configuration element is shown here with the default settings:
<section name="SecondLevelRetriesConfig" type="NServiceBus.Config.SecondLevelRetriesConfig, NServiceBus.Core"/>
...
<SecondLevelRetriesConfig Enabled="true"
TimeIncrease="00:00:10"
NumberOfRetries="3" />
You could also generate the SecondLevelRetriesConfig section using the Add-NServiceBus SecondLevelRetriesConfig PowerShell cmdlet.
Keep in mind that you may want to disable second-level retries, like first-level retries, during development for convenience, and then enable them in production.
Messages that expire
Messages that lose their business value after a specific amount of time are an important consideration with respect to potential failures.
Consider a weather reporting system that reports the current temperature every few minutes. How long is that data meaningful? Nobody seems to care what the temperature was 2 hours ago; they want to know what the temperature is now!
NServiceBus provides a method to cause messages to automatically expire after a given amount of time. Unlike storing this information in a database, you don't have to run any batch jobs or take any other administrative action to ensure that old data is discarded. You simply mark the message with an expiration date and when that time arrives, the message simply evaporates into thin air:
[TimeToBeReceived("01:00:00")]
public class RecordCurrentTemperatureCmd : ICommand
{
public double Temperature { get; set; }
}
This example shows that the message must be received within one hour of being sent, or it is simply deleted by the queuing system. NServiceBus isn't actually involved in the deletion at all, it simply tells the queuing system how long to allow the message to live.
If a message fails, however, and arrives at an error queue, NServiceBus will not include the expiration date in order to give you a chance to debug the problem. It would be very confusing to try to find an error message that had disappeared into thin air!
Another valuable use for this attribute is for high-volume message types, where a communication failure between servers or extended downtime could cause a huge backlog of messages to pile up either at the sending or the receiving side. Running out of disk space to store messages is a show-stopper for most message-queuing systems, and the TimeToBeReceived attribute is the way to guard against it. However, this means we are throwing away data, so we need to be very careful when applying this strategy. It should not simply be used as a reaction to low disk space!
Auditing messages
At times, it can be difficult to debug a distributed system. Commands and events are sent all around, but after they are processed, they go away. We may be able to tell what will happen to a system in the future by examining queued messages, but how can we analyze what happened in the past?
For this reason, NServiceBus contains an auditing function that will enable an endpoint to send a copy of every message it successfully processes to a secondary location, a queue that is generally hosted on a separate server.
This is accomplished by adding an attribute or two to the UnicastBusConfig section of an endpoint's configuration:
<UnicastBusConfig ForwardReceivedMessagesTo="audit@SecondaryServer" TimeToBeReceivedOnForwardedMessages="1.00:00:00">
<MessageEndpointMappings>
<!-- Mappings go here -->
</MessageEndpointMappings>
</UnicastBusConfig>
In this example, the endpoint will forward a copy of all successfully processed messages to a queue named audit on a server named SecondaryServer, and those messages will expire after one day.
While it is not required to use the TimeToBeReceivedOnForwardedMessages parameter, it is highly recommended. Otherwise, it is possible (even likely) that messages will build up in your audit queue until you run out of available storage, which you would really like to avoid. The exact time limit you use is dependent upon the volume of messages in your system and how much storage your queuing system has available.
You don't even have to design your own tool to monitor these audit messages; the Particular Service Platform has that job covered for you. NServiceBus includes the auditing configuration in new endpoints by default so that ServiceControl, ServiceInsight, and ServicePulse can keep tabs on your system.
Web service integration and idempotence
When talking about managing failure, it's important to spend a few minutes discussing web services because they are such a special case; they are just too good at failing.
When the message is processed, the email would either be sent or it won't; there really aren't any in-between cases.
In reality, when sending an email, it is technically possible that we could call the SMTP server, successfully send an email, and then the server could fail before we are able to finish marking the message as processed. However, in practice, this chance is so infinitesimal that we generally assume it to be zero. Even if it is not zero, we can assume in most cases that sending a user a duplicate email one time in a few million won't be the end of the world.
Web services are another story. There are just so many ways a web service can fail:
- A DNS or network failure may not let us contact the remote web server at all
- The server may receive our request, but then throw an error before any state is modified on the server
- The server may receive our request and successfully process it, but a communication problem prevents us from receiving the 200 OK response
- The connection times out, thus ignoring any response the server may have been about to send us
For this reason, it makes our lives a lot easier if all the web services we ever have to deal with are idempotent, which means a process that can be invoked multiple times with no adverse effects.
Any service that queries data without modifying it is inherently idempotent. We don't have to worry about how many times we call a service if doing so doesn't change any data. Where we start to get into trouble is when we begin mutating state.
Sometimes, we can modify state safely. Consider an example used previously regarding registering for alert notifications. Let's assume that on the first try, the third-party service technically succeeds in registering our user for alerts, but it takes too long to do so and we receive a timeout error. When we retry, we ask to subscribe the email address to alerts again, and the web service call succeeds. What's the net effect? Either way, the user is subscribed for alerts. This web service satisfies idempotence.
The classic example of a non-idempotent web service is a credit card transaction processor. If the first attempt to authorize a credit card succeeds on the server and we retry, we may double charge our customer! This is not an acceptable business case and you will quickly find many people angry with you.
In these cases, we need to do a little work ourselves because unfortunately, it's impossible for NServiceBus to know whether your web service is idempotent or not.
Generally, this work takes the form of recording each step we perform on durable storage in real time, and then query that storage to see which steps have been attempted.
In our example of credit card processing, the happy path approach would look like this:
- Record our intent to make a web service call to durable storage.
- Make the actual web service call.
- Record the results of the web service call to durable storage.
- Send commands or publish events with the results of the web service call.
Now, if the message is retried, we can inspect the durable storage and decide what step to jump to and whether any compensating actions need to be taken first.
If we have recorded our intent to call the web service but do not see any evidence of a response, we can query the credit card processor based on an order or transaction identifier. Then we will know whether we need to retry the authorization or just get the results of the already completed authorization.
If we see that we have already made the web service call and received the results, then we know that the web service call was successful but some exception happened before the resulting messages could be sent. In response, we can just take the results and send the messages without requiring any further web service invocations.
It's important to be able to handle the case where our durable storage throws an exception, rendering us unable to make our state persist. This is why it's so important to record the intent to do something before attempting it—so that we know the difference between never having done something and attempting it but not necessarily knowing the results.
The process we have just discussed is admittedly a bit abstract, and can be visualized much more easily with the help of the following diagram:
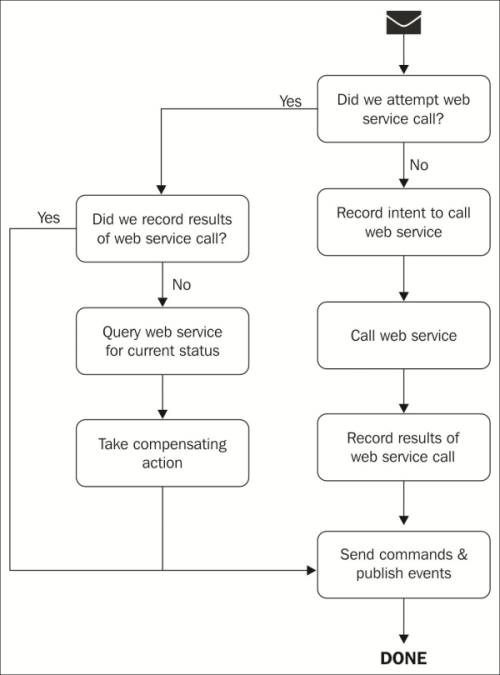
The choice of using the durable storage strategy for this process is up to you. If you choose to use a database, however, you must remember to exempt it from the message handler's ambient transaction, or those changes will also get rolled back if and when the handler fails.
In order to escape the transaction to write to durable storage, use a new TransactionScope object to suppress the transaction, like this:
public void Handle(CallNonIdempotentWebServiceCmdcmd)
{
// Under control of ambient transaction
using (var ts = new TransactionScope(TransactionScopeOption.Suppress))
{
// Not under transaction control
// Write updates to durable storage here
ts.Complete();
}
// Back under control of ambient transaction
}
Summary
In this article, we considered the inevitable failure of our software and how NServiceBus can help us to be prepared for it. You learned how NServiceBus promises fault tolerance within every message handler so that messages are never dropped or forgotten, but instead retried and then held in an error queue if they cannot be successfully processed. Once we fix the error, or take some other administrative action, we can replay those messages.
In order to avoid flooding our system with useless messages during a failure, you learned how to cause messages that lose their business value after a specific amount of time to expire.
Finally, you learned how to build auditing in a system by forwarding a copy of all messages for later inspection, and how to properly deal with the challenges involved in calling external web services.
In this article, we dealt exclusively with NServiceBus endpoints hosted by the NServiceBus Host process.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 South Africa
South Africa
 Thailand
Thailand
 Switzerland
Switzerland
 Slovakia
Slovakia
 Luxembourg
Luxembourg
 Hungary
Hungary
 Romania
Romania
 Denmark
Denmark
 Ireland
Ireland
 Estonia
Estonia
 Belgium
Belgium
 Italy
Italy
 Finland
Finland
 Cyprus
Cyprus
 Lithuania
Lithuania
 Latvia
Latvia
 Malta
Malta
 Netherlands
Netherlands
 Portugal
Portugal
 Slovenia
Slovenia
 Sweden
Sweden
 Argentina
Argentina
 Colombia
Colombia
 Ecuador
Ecuador
 Indonesia
Indonesia
 Mexico
Mexico
 New Zealand
New Zealand
 Norway
Norway
 South Korea
South Korea
 Taiwan
Taiwan
 Turkey
Turkey
 Czechia
Czechia
 Austria
Austria
 Greece
Greece
 Isle of Man
Isle of Man
 Bulgaria
Bulgaria
 Japan
Japan
 Philippines
Philippines
 Poland
Poland
 Singapore
Singapore
 Egypt
Egypt
 Chile
Chile
 Malaysia
Malaysia












