























































Drinking from the firehose
As you did earlier, you should grab the code from https://github.com/mlwithtf/MLwithTF/.
We will be focusing on the chapter_05 subfolder that has the following three files:
data_utils.pytranslate.pyseq2seq_model.py
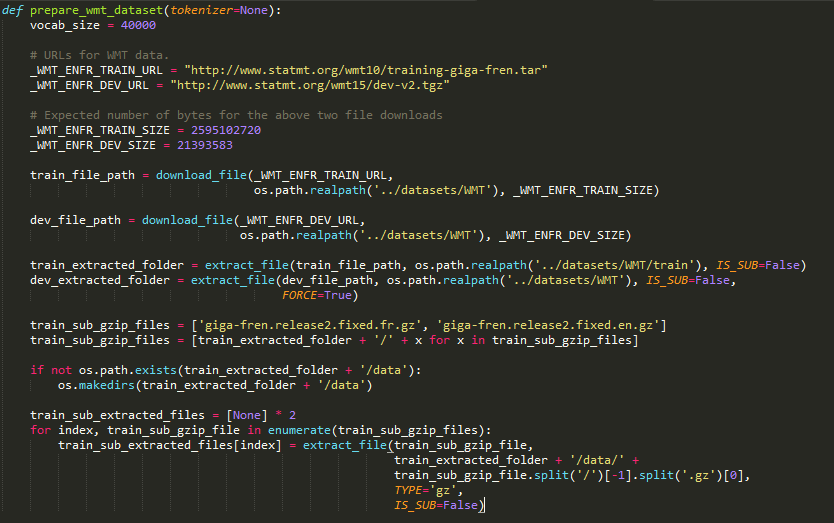
The first file handles our data, so let's start with that. The prepare_wmt_dataset function handles that. It is fairly similar to how we grabbed image datasets in the past, except now we're grabbing two data subsets:
giga-fren.release2.fr.gzgiga-fren.release2.en.gz
Of course, these are the two languages we want to focus on. The beauty of our soon-to-be-built translator will be that the approach is entirely generalizable, so we can just as easily create a translator for, say, German or Spanish.
The following screenshot is the specific subset of code:
Next, we will run through the two files of interest from earlier line by line and do two things—create vocabularies and tokenize the individual words. These are done with the create_vocabulary and data_to_token_ids...

















