























































SARSA and Q-learning
It is also very useful for an agent to learn the action value function
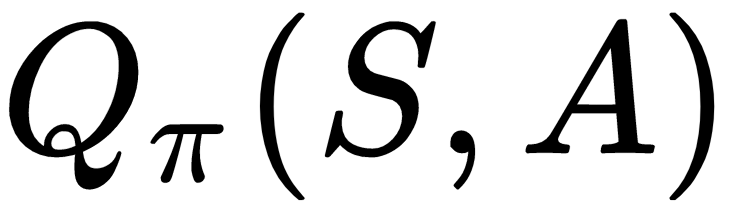
, which informs the agent about the long-term value of taking action

in state
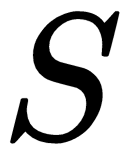
so that the agent can take those actions that will maximize its expected, discounted future reward. The SARSA and Q-learning algorithms enable an agent to learn that! The following table summarizes the update equation for the SARSA algorithm and the Q-learning algorithm:
Learning method | Action-value function |
SARSA | 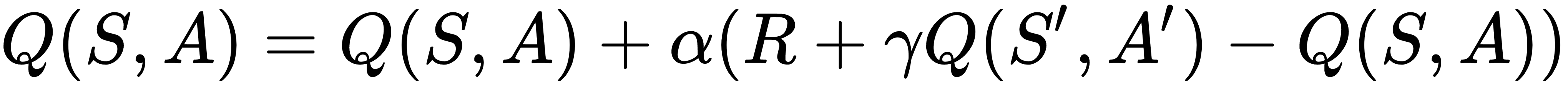 |
Q-learning | 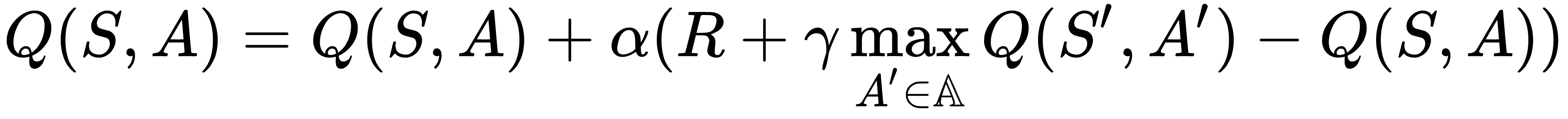 |
SARSA is so named because of the sequence State->Action->Reward->State'->Action' that the algorithm's update step depends on. The description of the sequence goes like this: the agent, in state S, takes an action A and gets a reward R, and ends up in the next state S', after which the agent decides to take an action A' in the new state. Based on this experience, the agent can update its estimate of Q(S,A).
Q-learning is a popular off-policy learning algorithm, and it is similar to SARSA, except...

















