























































Monte Carlo methods
In this section, we'll describe our first algorithm, which does not require full knowledge of the environment (model-free): the Monte Carlo (MC) method (yay, I guess...). Here, the agent uses its own experience to find the optimal policy.
Policy evaluation
In the Dynamic programming section, we'll describe how to estimate the value function,
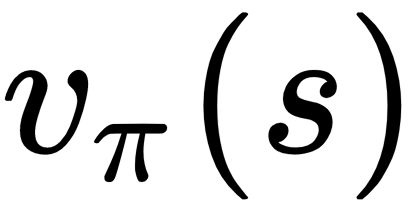
, given a policy, π (planning). MC does this by playing full episodes, and then averaging the cumulative returns for each state over the different episodes.
Let's see how it works in the following steps:
- Input the policy, π.
- Initialize the following:
- Thetable with some value for all states

- An empty list of
returns(s)for each state, s
- The
- For a number of episodes, do the following:
- Generate a new episode, following policy π:
s0, a0, r1, s1, a1, r2, s2, a2, r3, ... aT-1, rT, sT. - Initialize the cumulative discounted return,
G = 0. - Iterate over each
tstep of the episode, starting fromT-1and going to0:- Update G with the reward at the t+1 step...
- Generate a new episode, following policy π:

















